
[:it]Lo schema di un canale trasmissivo può essere visto come segue:
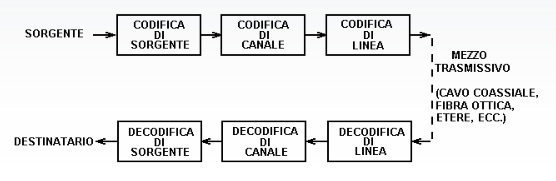
La codifica di sorgente ha il compito di trasformare un messaggio scritto ad esempio in una tastiera in una sequenza di bit.
Tale trasformazione può essere a lunghezza fissa (codice ASCII) o a lunghezza variabile (ad esempio codifica di Huffmann)
Ci sono i pregi e i difetti per entrambi i tipi di decodifica.
Codice ASCII.
Esso permette la codifica dei caratteri in 8 bit. Utilizzando la definizione di distribuzione a ripetizione avendo un alfabeto di 2 cifre per 8 bit in tutto si ha  combinazioni diverse.
combinazioni diverse.
Codice Huffmann
Il codice di Huffman costruisce una tabella di codifica-decodifica utilizzando un numero di bit differente a seconda della probabilità che si ha di trovare uno specifico valore.
Utilizzando meno bit per i codici più probabili, e più bit per quelli meno diffusi, si può risparmiare memoria.
E’ il codice migliore per ottimizzare l’entropia, è il metodo più efficiente per la compressine dei dati. (pkzip, jpeg, mp3).
Per creare la giusta codifica si usa uno schema ad albero
Ecco la spiegazione dell’algoritmo:
- si ordinano i simboli in ordine decrescente di probabilità
- i due valori più piccoli creano le prime due foglie (leaf node) e si sommano creando il primo nodo. A ramo di sinistra si associa sempre il valore 0 ed al ramo di destra il valore 1.
- si ordinano nuovamente i valori.
- i due valori più piccoli si sommano creando ancora un nodo, Al ramo di sinistra si associa il valore 1, al ramo di destra il valore 0.
- il processo continua finchè non vi sono più simboli o probabilità associati al relativo simbolo.
Esempio
Sia dato un file formato da 120 caratteri con la seguente frequenza di caratteri (attenzione parlare di frequenza o probabilità di un carattere è uguale)
| carattere | a | b | c | d | e | f |
| frequenza | 57 | 13 | 12 | 24 | 9 | 5 |
Se si usasse un codice a lunghezza fissa si dovrebbe usare una stringa di bit lunga 3 in quanto essa è l’unica che possa contenere la codifica di 6 caratteri, infatti 
| carattere | a | b | c | d | e | f |
| codice fisso | 000 | 001 | 010 | 011 | 100 | 101 |
Siccome vi sono 120 caratteri da trasmettere  bit
bit
Utilizzando invece la codifica a lunghezza variabile si ha:
| carattere | a | b | c | d | e | f |
| frequenza | 57 | 13 | 12 | 24 | 9 | 5 |
| codice variabile | 0 | 101 | 100 | 111 | 1101 | 1100 |
Bastano  bit
bit
Spiegazione di come si crea il codice variabile.
- ordino i valori dal meno frequente al più frequente:
| f:5 | e:9 | c:12 | b:13 | d:24 | a:57 |
- sommo gli ultimi due

- creo due foglie con il ramo 0 a sinistra 0 ed il ramo 1 a destra
- ordino la sequenza:
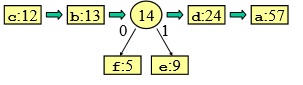
- sommo gli ultimi due

- creo due foglie con il ramo 0 a sinistra e il ramo 1 a destra
- ordino la sequenza
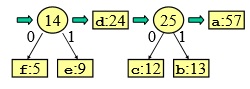
- sommo gli ultimi due

- creo un nuovo nodo
- ordino la sequenza
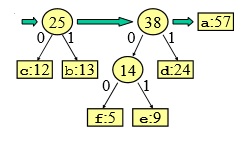
- sommo gli ultimi due

- creo un nuovo nodo
- ordino la sequenza
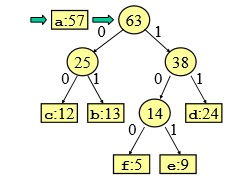
- sommo gli ultimi 2

- creo l’ultimo nodo
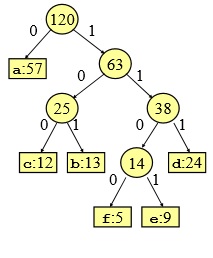 Adesso come si legge il codice?
Adesso come si legge il codice?
- o partendo dal basso e poi invertendo i bit: ad esempio f: 0011 lo inverto 1100
- o partendo dall’alto (root) ed arrivando a tutte le radici
| carattere | a | b | c | d | e | f |
| frequenza | 57 | 13 | 12 | 24 | 9 | 5 |
| codice variabile | 0 | 101 | 100 | 111 | 1101 | 1100 |
Come avviene la decodifica?
Siccome nessuna parola codice è prefisso di un’altra, la prima parola codice del file codificato risulta univocamente determinata.
Ad esempio trasmetto 0101100, comincio a leggere da sinistra verso destra. Prendo i primi 4 caratteri, non corrisponde a nessuna cifra, prendo i primi tre ancora nessuna, prendo il primo e corrisponde ad a, elimino lo 0 rimane
101100
1011 non corrisponde a nessun carattere,
101 corrisponde alla b
rimane 100 che corrisponde alla c
per cui il messaggio è abc.[:]