Crea una pagina web con l’organigramma di un’azienda partendo dall’ammistratore delegato, poi dalla segreteria, poi ufficio tecnico con il relativo personale. Per fare questo usa le opportune liste. Poi cliccando sul nome mostrare la relativa immagine con pochi dati. Cerca sul web delle immagini a caso e inventa tu i dati anggrafici.
es2.
Crea il sito di un museo di arte contemporanea strutturandolo con delle liste per indicare le sale e poi cliccando sulla relativa sala si apre una nuova pagina che mostra alcuni quadri prsenti. Crea un link per ritornare alla pagina precedente. Le immagini ed il museo cercare nel web
es3,
Crea il sito per un torneo di calcio. Cliccando sul nome della squadra mostrare una nuova pagina in cui compare l’elenco dei calciatori e dell’allenatore ed inserire le immagini. Le immagini cercare sul web
es4.
crea una pagina web, usando le liste, possa mostrare le ricette tipiche della regione trentino alto adige. Usa delle opportune immagini per mostrare le ricette e cliccando sugli ingredienti dove si possono acquistare.
es5.
Crea una pagina web che illustri le cinque terre. Cliccando sulle cinque terre si deve aprire la pagina web di wikipedia della liguria.
L’elenco delle cinque terre deve essere con la relativa immagine.
All’interno del tag body si possono creare vari tipi di liste:
Elenco a pallini:
<ul>
<li> primo
<li> secondo
<li> terzo
</ul>
Elenco a quadratini
<ul type=”square”>
<li>primo
<li>secondo
<li>terzo
</ul>
Elenco a pallini vuoti
<ul type =”circle”>
<li> Primo
<li>Secondo
<li> Terzo
</ul>
Elenco strutturato
si nota come il tag <ol> apra l’elenco strutturato poi al suo interno si mette il primo elemento della lista e poi ancora il tag <ul> per gli altri elementi.
Di fronte
alla Chiesa di San Nicola parte la
Via Nerudova, la più bella di Praga, che con un po’ di fatica
ma tanta gioia per gli occhi porta fino al Castello. La Nerudova prende il nome
da Jan Neruda, il poeta praghese da cui il più famoso Pablo Neruda preso lo
pseudonimo. Lungo la Nerudova ci sono alcuni dei palazzi più belli di Malà
Strana e di tutta Praga quasi tutti trasformati in pub, negozi di souvenir e
hotel. Al numero 5 c’è uno dei palazzi più belli, Palazzo Morzin che ospita
l’ambasciata rumena: ve ne accorgete dai due atlanti giganti che reggono un
balcone. Al numero 12 c’è la “Casa
ai tre violini”, dove vissero tre famiglie di liutai. Si
racconta che nelle notti di luna piena si senta ancora un violino suonare.. Al numero 20 c’è Palazzo Thun,
sede dell’ambasciata italiana. Il leone d’oro del numero 32 accoglie chi vuole
visitare il Museo della
Farmacia mentre al numero 44 le inquietanti aquile nere
raccontano dello spirito di una vecchia vissuta in quella casa per quasi un
secolo e che anche dopo la sua morte non vuole abbandonarla..
Ponte Carlo
Ponte
Carlo è una delle principali attrazioni turistiche di Praga ed è anche molto
amato dagli artisti locali, musicisti e venditori di souvenir che vi collocano
le loro bancarelle su entrambe i lati tutto l’anno. Per questo motivo durante
le ore diurne il ponte è decisamente affollato.Il momento più romantico per
visitare il ponte é senz’altro il tramonto, quando si può godere di una vista
mozzafiato dell’intero Castello di Praga che si illumina nel cielo che
lentamente si fa buio e questa immagine stupenda si riflette nelle acque del
fiume.Purtroppo, anche al tramonto sarete in compagnia di molti altri turisti
che, come voi, vogliono godere delle ore magiche del calar del sole, ma
probabilmente se ne saranno già andati artisti e venditori. Per visitare il Ponte
Carlo vuoto occorre andarci la notte tardi o nelle prime ore del mattino.
Storia
A
partire dal 1683 fino al 1918 furono collocate statue e gruppi scultorei su
entrambi i lati del Ponte Carlo, che oggi sono in totale 30; molte di esse sono
solo delle copie e quelle originali sono custodite al Lapidarium del Museo
Nazionale a Vyšehrad.La statua probabilmente più celebre, nonché la più antica,
é quella del martire ceco San Giovanni Nepomuceno, che fu giustiziato e gettato
dal ponte durante il regno di Venceslao IV per non aver voluto rivelare ciò che
gli aveva detto la regina durante la confessione. La lapide sulla statua é
stata consumata dall’enorme numero di persone che l’hanno toccata nel corso dei
secoli perché si dice porti fortuna e assicuri il proprio ritorno a Praga.Altre
statue degne di nota raffigurano: San Venceslao: al santo patrono di Boemia
sono state dedicate ben tre statue, di cui una da bambino e una in compagnia
dei Santi Sigismondo e Norberto San Vito: santo patrono di Praga, nonchè dei
danzatori, attori, commedianti e… cani La Visione di Santa Lutgarda: questa
statua, raffigurante Cristo che appare alla santa ceca e le concede di
baciargli le ferite, è considerata la migliore tra tutte le statue del Ponte
Carlo Santi Cirillo e Metodio: è la statua più recenteÈ stata dedicata una
statua anche a San Giuda Taddeo, protettore delle cause senza speranza. Come
vedete, chiunque può avere un motivo valido per visitare il ponte più famoso di
Praga! – https://www.praga.info/cosa-vedere-praga/ponte-carlo/
Cosa vedere nel Castello
Il castello ha numerosi edifici con un’importante valore storico
ed artistico; questi sono alcuni dei più importanti:
Cattedrale di San Vito: Con un’importante storia e un
grande valore artistico, la Cattedrale di San Vito è il simbolo di Praga e di tutta
la Repubblica Ceca.
Il Vicolo d’Oro: Il piccolo Vicolo d’Oro è uno degli angoli più affascinanti che si trovano
all’interno del recinto del castello. Con case colorate, in passato
occupate da orefici, attualmente accoglie numerosi negozi d’artigianato.
Antico Palazzo Reale: Costruito in legno nel
IX secolo, l’antico palazzo soffrì, nel corso dei secoli, vari
cambiamenti, fino a trasformarsi nell’impressionante edificio che oggi si
può vedere.
La Basilica e il Convento di San
Giorgio:
Fondata nel 920, l’antica basilica fu ampliata nel 973 con la costruzione
del convento, che attualmente accoglie la collezione d’arte boema del XIX
secolo della Galleria Nazionale di Praga.
Torre Daliborka: Famosa prigione della città,
che all’inizio accoglieva i membri della nobiltà, per poi trasformarsi in
una prigione per qualsiasi classe sociale.
Torre Negra: Conosciuta con questo nome per un
incendio che la fece diventare nera, questa torre funzionò come prigione
per i debitori, ovvero per quei prigionieri che potevano usufruire di
numerosi privilegi.
Torre Bianca: In passato era utilizzata come
prigione per i nobili.
Torre delle Polveri: Costruita nel XV secolo, come
parte della fortificazione del castello, questa torre divenne il
laboratorio degli alchimisti del monarca Rodolfo II.
Malá Strana in ceco significa “Parte Piccola”
Di solito si arriva a Malà Strana attraversando il Ponte
Carlo: superate le due torri
gotiche si imbocca la via Mostecka, la via imperiale che percorrevano i sovrani
prima di essere incoronati. La Mostecka porta dritta verso il cuore di Malà
Strana, la Malostranske Namestì, Piazza Malastrana, divisa in due dalla Chiesa di San Nicola, la più bella chiesa Barocca di Praga. Questa San Nicola è da non confondere con
l’omonima chiesa che si trova a Stare Mesto, la Città Vecchia.
Piazza San venceslao
Jan Palach
La casa natale di Franz Kafka potete trovarla al numero 3 di Namesti Franze Kafky, nel quartiere Staré Město. E’ raggiungibile con la metro, scendere alla fermata STAROMESTSK
sabato 30
mattina
Visita al Municipio e all’Orologio Astronomico
Piazza San Venceslao
teatro di importanti eventi storici oggi Piazza
Venceslao nella Città Nuova è il centro dello shopping e del divertimento
notturno a Praga.
Eventi storici
Nata come Mercato dei Cavalli (Konský trh) nel
1348 per volontà di Carlo IV, Piazza San Venceslao ha ricevuto il suo nome
attuale durante la Rinascita Nazionale Ceca del 1848. I praghesi ne abbreviano
il nome in “Václavák“.Nel corso dei secoli questo viale ha sempre rivestito un
grande significato come luogo di raduni, manifestazioni ed importanti avvenimenti
che hanno segnato la storia ceca. Ecco i più importanti eventi storici avvenuti
in Piazza San Venceslao:durante i moti rivoluzionari del 1848 si tenne una
messa che ebbe un’enorme affluenza di pubbliconel 1918 venne celebrata la
creazione del nuovo stato cecoslovaccoil 16 gennaio 1969 lo studente
universitario Jan Palach si dette fuoco in segno di protesta contro
l’oppressione socioculturale perpetrata dall’Unione Sovietica, dando inizio a
quel movimento che sarebbe poi rimasto noto come Primavera di Pragail 17
novembre 1989 i cittadini praghesi, stanchi dell’oppressione comunista, si
riunirono in piazza, dando inizio agli eventi che portarono la settimana
successiva alla caduta del comunismo.Ancora oggi la statua equestre di San
Venceslao, alla sommità della piazza, è il punto di ritrovo piú popolare tra i
cittadini di Praga che si danno appuntamento “al cavallo” (u kone) o “sotto la
coda” (pod ocasem). –
Sotterranei di Praga
Il luogo d’incontro è presso l’ufficio
dell’operatore locale. L’ufficio è situato all’interno dell’Art Passage, sul
lato ovest di Piazza della Città Vecchia (accanto all’hotel “U
Prince”). Una volta lì, imbocca il passaggio sul lato sinistro. Indirizzo:
Male Namesti 459/11, Praha 1, 110 00. GPS: N 50.086499, E 14.419744
Il tour è disponibile tutti i giorni alle
11:00, alle 13:00 e alle 17:00.
Casa Danzante
casa danzante
Costruita tra il 1992 e il 1996 su commissione
di una ditta di assicurazioni, la Casa Danzante ha riempito un vuoto lasciato
da un edificio distrutto il 14 febbraio 1945 durante un bombardamento aereo di
Praga da parte degli americani.Il progetto fu affidato dell’architetto croato
croato Vlado Milunić in cooperazione con l’architetto e designer di fama
mondiale Frank Gehry, mentre gli interni sono stati parzialmente progettati da
Eva Jiřičná, un inglese di origine ceca.La proposta di realizzare un centro culturale
all’interno della Casa Danzante venne abbandonata: di artistico rimane solo una
galleria, con mostre e negozio di libri.Oggi l’edificio ospita perlopiù uffici,
compresi quelli di imprese multinazionali, oltre a una caffetteria e un
ristorante di lusso con terrazza da cui si gode di una bella vista. Due piani
di questo iconico edificio sono occupati da un design hotel.
Come raggiungere la Casa Danzante
Il celebre edificio Fred e Ginger si trova sul
lungofiume Rašínovo nábřeží, nella Città Nuova. Si può facilmente raggiungere
la zona con il tram.
Venerdì 29
Josefov, il Quartiere Ebraico
Vecchio cimitero ebraico
Široká, Staré Město, 110 00 Praha-Praha 1,
Repubblica Ceca
Sinagoga Vecchia-Nuova
Quartiere ebraico e visita alle sinagoghe
Domenica 1
Ritorno a Bolzano
Note di trasporto
Biglietti
Il sistema di trasporto pubblico di Praga utilizza due
tipi di biglietto.
• Biglietto
di 30 minuti: 24 CZK
• Biglietto di 90 minuti: 32 CZK
Adulti: 24 CZK
Bambini 6-15 anni: 12 CZK
Bambini al di sotto dei 6 anni: gratuito
Adulti: 32 CZK
Bambini 6-15 anni: 16 CZK
Bambini al di sotto dei 6 anni: gratuito
I biglietti possono essere usati su ogni mezzo pubblico, consentono trasferimenti tra linee diverse (tra linee della
metropolitana, da tram a tram, ecc.) e mezzi diversi (da
metropolitana a tram, da tram ad autobus, ecc.). e sono validi per 30/90 minuti dalla convalida.
I biglietti sono venduti da macchine automatiche di colore giallo situate
ad ogni fermata della metropolitana (istruzioni anche in
inglese, solo monete), presso le biglietterie in alcune
fermate della metropolitana, nei Tabák/Trafika (tabaccaio),
in alcune edicole e negli uffici del turismo. Potete anche comprare un biglietto usando il vostro telefono cellulare e mandando un sms con scritto “DPT24” o “DPT32” al numero 90206. Nel giro di un minuto, riceverete il vostro biglietto via sms.
Il biglietto deve essere timbrato all’ingresso
della metropolitana e sui i tram e autobus per segnalare
l’inizio del periodo
di validita.
All’interno della manifestazione che si terrà da venerdì 15 a sabato 16, vi sarà il mio intervento che verterà sull’utilizzo di un Raspberry con AccessPoint per fornire un segnale WiFi in una zona utilizzando il proxy e LDAP presente nel server, senza usare dhcp del raspberry.
Scrivere
un programma che svolga le seguenti operazioni:
Inserire all’utente 10 numeri;
Contare e stampare a video la quantità di numeri positivi e quella di numeri negativi inseriti;
Eseguire e stampare a video la somma dei numeri positivi e quella dei numeri negativi.
Soluzione:
#include<iostream>
using namespace std;
int main()
{
int i,num,nummin,nummag,sommin,sommag;
i=0;
nummin=0;
nummag=0;
while(i!=10)
{
cout<<“Inserisci il numero: “;
cin>>num;
if (num<10)
{
nummin=nummin+1;
sommin=sommin+num;
}
else
{
nummag=nummag+1;
sommag=sommag+num;
}
i=i+1;
}
cout<<"Numeri minori di dieci: "<<nummin<<" con somma: "<<sommin<<endl;
cout<<"Numeri maggiori di dieci"<<nummag<<" con somma: "<<sommag<<endl;
return0; Code language:JavaScript(javascript)
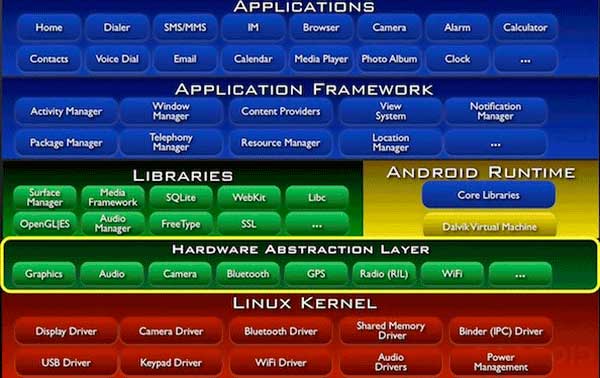
Prima di sviluppare un’app, bisogna capire com’è strutturato il sistema operativo.
Stack Android:
Linux Kernel Layer
Native Layer
Application Framework Layer
Application Layer
Tutte le applicazioni sono scritte in Java che si basano su framework applicativo pieno di librerie e classi astratte che utilizzano l’ambiente Apache Harmony. Tutte le funzioni quali mandare un sms, usare internet si basa su librerie scritte in C++.
Hardware Abstraction Layer (HAL) è formato da un insieme di funzioni che tine conto delle differenze fisiche dei vari dispositivi. Permette al software di funzionare su dispositivi differenti.
Le applicazioni vengono eseguite tramite DVM Dalvik Virtual Machine una macchina virtuale adattata per l’uso dei dispositivi mobili. Dalla versione 5.0 è stata sostituita da ART (android Run Time)
Applicazioni
Le applicazioni, più comunemente dette app, sono dei programmi ti tipo Event Driven ossia guidate dagli eventi gestiti all’interno del dispositivo mobile come il touch dello schermo, le azioni dei sensori, ecc.
2 tipi:
applicazioni vere e proprie che occupano tutto lo schermo come ad esempio il browser
widget che occupano una piccola e fissata porzione dello schermo come ad esempio l’orologio di Android
le applicazioni sono composte da 4 componenti:
Activity
Service
Broadcast Receiver
Content Provider
Le applicazioni devono sempre contenere un’activity.
Activity
Blocco di codice che interagisce con l’utente utilizzando lo schermo e i dispositivi di input, usando i pulsanti, le caselle di testo, pulsanti radio, ecc presenti nell’android .widget. Esse vengono usate ereditando la classe android.app.Activity.
Service
Programmi eseguiti in background e non interagiscono con l’utente, ad esempio la riproduzione di un mp3. Esse estendo la classe android.app.Service
Broadcast Receiver
Si usa quando si deve intercettare un evento di sistema, ad esempio si scatta una foto o parte il segnale di batteria scarica Si estende la classe android.content.BroadcastReceiver
Content Provider
Espongono i dati e le informazioni, è il canale di comunicazione tra le differenti applicazioni installate nel sistema. Si estende la classe android.content.Content Provider
Nota Bene: un’applicazione ha al suo interno le activity
Approfondimenti su Activity
I sistemi Android non possiedono schermi come quelli del PC per cui le finestre vengono affiancate solo parzialmente.
Le activity passano attraverso i seguenti stati:
Resumed o Active o Running: è visibile e riceve i dati in input
Paused: è parzialmente visibile, non riceve input
Stopped: non è visibile ma ancora in esecuzione
Destroyed: è rimossa dalla memoria del dispositivo
L’attività che occupa il display è in esecuzione e interagisce con l’utente, le altre attività sono ibernate per ridurre al minimo il consumo delle risorse.
Metodi della classe Activity
protect void onCreate(android.os.BundlesavedInstanceState) –> viene richiamato alla creazione dell’attività, l’argomento savedInstanceState restituisce al metodo un eventuale stato dell’attività passato ad un’altra istanza che è stata terminata. E’ null se non vi è alcuno stato precedentemente salvato.
protect void onRestart()–> segnala che l’attività è stata riavviata dopo che è stata arrestata.
protect void onStart()–> segnala che l’attività viene resa visibile allo schermo
protect void onResume()–>segnala che l’attività inizia ad interagire con l’utente.
protect void onPause()–> l’attività con l’utente termina
protect void onStop()–>attività non più visibile sullo schermo
protect void onDestroy()–>applicazione terminata
Per poter modificare il codice di questi metodi dobbiamo eseguire un override del metodo della classe madre, prestando attenzione ad inserire, nella prima riga di codice il costruttore della classe attraverso l’operatore super.
File APK
Le app vengono distribuite sotto forma di pacchetto autoinstallante in un file con estensione .APK (android Package), è un file compresso.
All’interno del file c’è un certificato che permette l’installazione di un pacchetto .APK su Abdroid: il certificato deve essere presente in qualsiasi pacchetto, altrimenti Android non installerà nulla.
Il certificato viene creato dallo sviluppatore può crearne di due tipi: uno di debagging (ad uso interno) oppure un di mercato (per al distribuzione) ed in questo caso se la copia sarà libera oppure limitata.
Il distributore aggiunge una sua chiave e permetterà la distribuzione. Oppure lo sviluppatore si autocrea un certificato ed in fase di installazione comparirà un messaggio “a suo rishio e pericolo”)
Software Development Kit (SDK) per Apple si chiama Xcode che permette di sviluppare applicazioni per iPhone e iPod e testarle in un simulatore.
Unico inconveniente è che per poter caricare un’applicazione nei dispositivi è necessario iscriversi (a pagamento) all’iPhone Developer Program o se lo sviluppatore vuole mettere a disposizione gratis la sua app allora non è previsto alcun costo di rilascio o distribuzione.
Xcode supporta la distribuzione in rete del lavoro di compilazione tramite Bonjour e Xgrid: compilare un progetto su più computer riducendo i tempi e inoltre la compilazione è di tipo incrementale, cioè il codice viene compilato mentre viene scritto, ottimizzando i tempi.
SDK per Android
Android Studio sta cominciando a sostituire Eclipse.
Se lancio una moneta tre volte, voglio sapere in quante disposizioni differenti posso avere i risultati, immaginando che potrei avere anche tre volte testa e tre volte croce.
Tutte le possibili disposizioni sono le seguenti:
TTT, TTC, TCT, TCC, CTT, CTC, CCT, CCC.
Un altro esempio è quante sono le possibili disposizioni in una sicura considerando che si hanno dieci cifre e quattro rulli?

















 ossia 10.000 combinazioni diverse.
ossia 10.000 combinazioni diverse.

 e
e 
 ed utilizzo la formula precedente effettuando il prodotto di tutti i numeri interi compresi tra 15 e 2 compresi:
ed utilizzo la formula precedente effettuando il prodotto di tutti i numeri interi compresi tra 15 e 2 compresi: