Siconsideri, tra le armature, un piano perpendicolare all’asse di simmetria.
Su tale piano, sia C la circonferenza avente centro sull’asse e raggio r.
Determinare la circuitazione di B lungo C
Ricavare che il flusso di E, attraverso la superficie circolare delimitata da C, è dato da:
Calcolare la d.d.p. tra le armature del condensatore.
A quale valore tende B al trascorrere del tempo?
Giustificare la risposta dal punto di vista fisico
Prerequisiti
conoscenza della circuitazione del campo magnetico lungo una circonferenza
risolvere integrale di una funzione composta.
risolvere limiti
Sviluppo
Primo punto
La circuitazione di B lungo una circonferenza è:
Secondo punto
Per ricavare il flusso di E si applica la definizione di Ampere-Maxwell e si calcola un integrale:
dalla quale:
adesso sostituisco il valore di dato in precedenza e calcolo il valore dell’integrale:
Mi concentro solo sull’integrale:
All’inizio il potenziale è nullo ossi significa che anche il flusso è nullo per cui nell’integrale precedente quando t=0 anche il flusso è nullo per cui:
Unendo tutte le relazioni ho alla fine:
Terzo punto
usando la definizione precedente di flusso la differenza di potenziale diventa:
Quarto punto
Devo saper sviluppare il limite:
quindi il campo magnetico con t che tende ad infinito tende ad annullarsi.
Quinto punto
Con il passare del tempo si nota che la tensione ai capi del condensatore tende ad un valore costante come pure il campo elettrico per cui non si ha più una variazione di flusso e quindi il campo magnetico scompare.
Un condensatore piano è formato da due armature circolari di raggio R, poste a distanza d, dove R e d sono espresse in metri (m). Viene applicata alle armature una differenza di potenziale variabile nel tempo e inizialmente nulla.
All’interno del condensatore si rileva la presenza di un campo magnetico B.
Trascurando gli effetti di bordo, a distanza r dall’asse di simmetria del condensatore, l’intensità di B, espressa in tesla(T), varia secondo la legge:
con
dove e sono costanti positive e è il tempo trascorso dall’istante iniziale, espresso in secondi (s).
Dopo aver determinato le unità di misura di a e k
spiegare perché nel condensatore è presente un campo magnetico anche in assenza di magneti e correnti di conduzione
Qual è la relazione tra le direzioni di B e del campo elettrico E nei punti interni al condensatore?
Prerequisiti
conoscenza delle unità di misura che caratterizzano il campo induzione magnetica
conoscenza della legge di Ampere Maxwell o quarta equazione di Maxwell.
Sviluppo
Primo punto
Si parte dalla relazione espressa solo in funzione delle unità di misura:
dove è espressa inevitabilmente in secondi.
Per cui
Secondo punto
Si applica la legge di Ampere-Maxwell considerando nullo le correnti che non sono presenti in questo caso:
essendovi la circuitazione vi è il campo magnetico.
Terzo punto
Le linee di campo elettrico sono perpendicolari alle armature mentre quelle di campo magnetico sono concentriche rispetto al centro del condensatore e sono perpendicolari a quelle elettriche.
Si supponga, in assenza dei tre fili, che il contorno della regione S rappresenti il profilo di una spira conduttrice di resistenza R = 0,20 Ω. La spira è posta all’interno di un campo magnetico uniforme di intensità perpendicolare alla regione S. Facendo ruotare la spira intorno all’asse x con velocità angolare ω costante, in essa si genera una corrente indotta la cui intensità massima è pari a 5,0mA. Determinare il valore di ω.
Prerequisiti
conoscenza della legge di Faraday Neumann applicata ad una superficie in rotazione che è equivalente ad un campo magnetico sinusoidale.
Sviluppo
La legge di Faraday Neumann dice che:
è costante
ed è l’unico termine che varia con il tempo per cui la sua derivata risulta:
Si supponga che nel riferimento Oxy le lunghezze siano espresse in metri (m).
Si considerino tre fili conduttori rettilinei disposti perpendicolarmente al piano Oxy e passanti rispettivamente per i punti:
; e
I tre fili sono percorsi da correnti continue di intensità , e . Il verso di è indicato in figura mentre gli altri due versi non sono indicati.
Stabilire come varia la circuitazione del campo magnetico, generato dalle correnti , e , lungo il contorno di S, a seconda dell’intensità e del verso di e di .
Prerequisiti
conoscenza della circuitazione del campo elettrico
capre come poter determinare come un punto stia all’interno di una regione.
Sviluppo
La definizione di circuitazione è la seguente:
Ossia la circuitazione dell’induzione magnetica lungo un percorso chiuso, con cui risulta concatenata la corrente che genera il campo è sempre uguale al prodotto della permeabilità elettrica per l’intensità di corrente, qualunque sia la forma geometrica del percorso chiuso.
Questo significa che a prescindere dalla forma della superficie trovata devo calcolare la corrente concatenata (compresa) nella zona delimitata dalla superficie.
La circuitazione dell’induzione magnetica, calcolata lungo un cammino chiuso qualsiasi, è uguale al prodotto della permeabilità magnetica per la somma algebrica delle correnti concatenate.
Nel caso specifico quali dei tre fili sono compresi nella superficie delimitata dalle due curve? Se si avesse il grafico così preciso si fa presto a rispondere a questa domanda ma lo si può fare anche in maniera analitica.
Il punto è posizionato più in basso rispetto alla curva ma verifico che sia più in alto della curva .
per cui è all’interno della regione S.
Il punto è posizionato più in alto rispetto alla curva ma verifico che sia più in basso della curva .
per cui è all’interno della regione S.
Il punto è posizionato più in basso rispetto alla curva ma verifico che sia più in basso della curva .
per cui è al di fuori della regione S e non deve essere considerata per il calcolo della circuitazione.
quindi quando le correnti hanno verso opposto la circuitazione diminuisce fino ad annullarsi quando hanno lo stesso valore altrimenti aumenta nel caso in cui le due correnti hanno lo stesso verso.
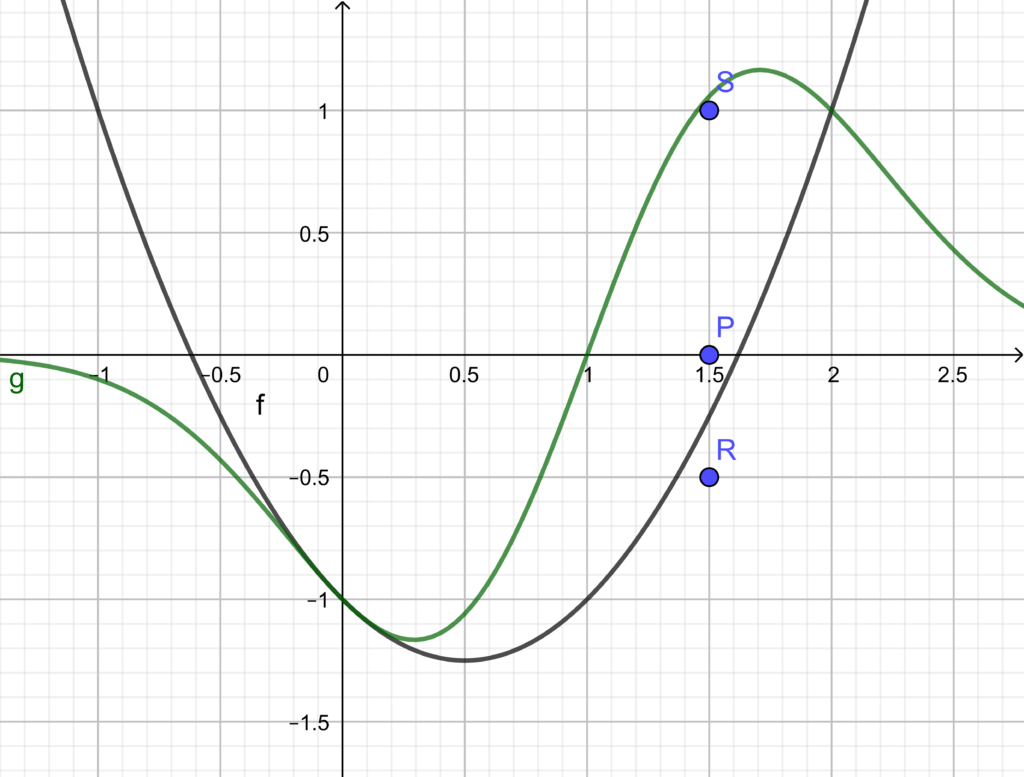
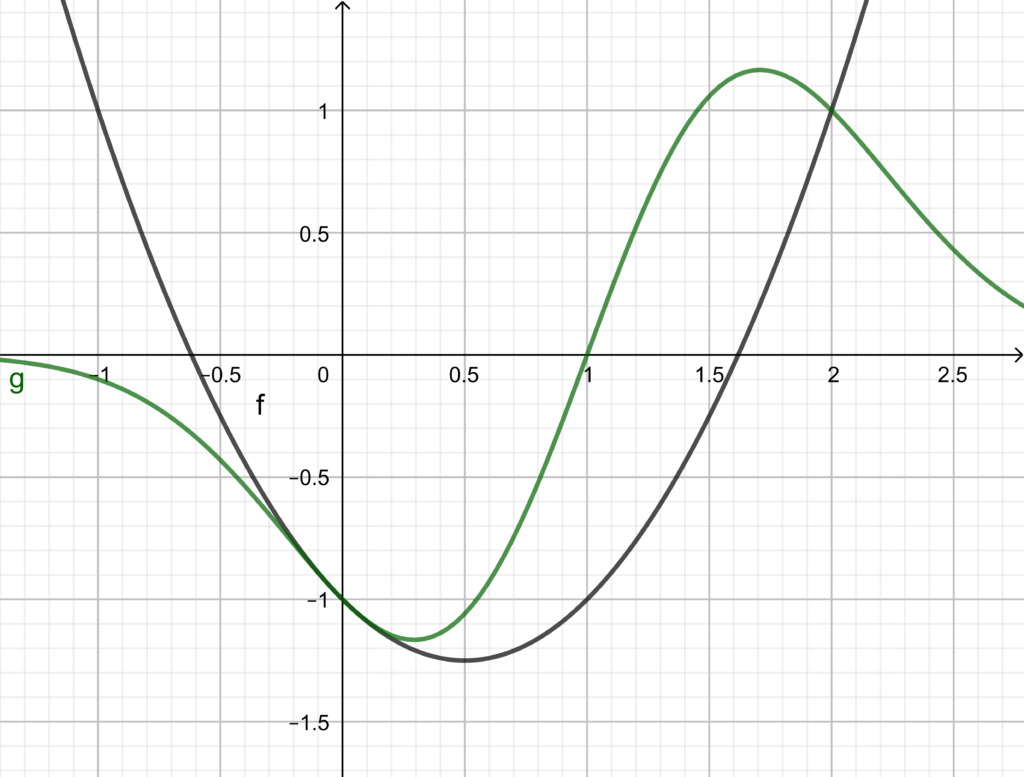
Provare che, comunque siano scelti i valori di e in con , la funzione g ammette un massimo e un minimo assoluti. Determinare i valori di a e b in corrispondenza dei quali i grafici delle due funzioni f e g si intersecano nel punto A(2,1).
Prerequisiti
saper fare la derivata prima
segno della derivata prima
risolvere un sistema d’equazioni
Sviluppo
Sviluppo la prima parte facendo la derivata prima di .
annullo la derivata per determinare i potenziali punti di massimo o di minimo
posso eliminare l’esponenziale perchè si annulla solo all’infinito e rimane:
si nota che la quantità sotto la radice è sempre positiva per cui si hanno sempre due valori che potranno essere un massimo ed un minimo.
Per verificare che siano anche massimo o minimo assoluti devo verificare che:
Applicando De L’Hospital:
Adesso sviluppo la seconda parte:
Sostituisco le coordinate di A(2,1) in f ed in g e risolvo il relativo sistema:
Risolvendola con il metodo che si preferisce si ha:
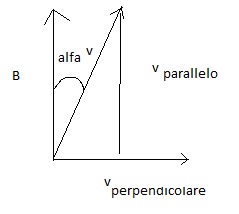
Un protone penetra in una regione di spazio in cui è presente un campo magnetico uniforme di modulo .
Esso inizia a muoversi descrivendo una traiettoria ad elica cilindrica, con passo costante , ottenuta dalla composizione di un moto circolare uniforme di raggio r=10.5 cm e di un moto rettilineo uniforme. Determinare il modulo del vettore velocità e l’angolo che esso forma con .
Prerequisiti
conoscenza della forza di Lorentz
moto circolare
scomposizione dei vettori velocità
Sviluppo
Forza di Lorentz
Essendo un moto elicoidale si deve tener presente questo schema:
In laboratorio si sta osservando il moto di una particella che si nuove nel verso positivo dell’asse x di un sistema di riferimento ad esso solidale.
All’istante iniziale, la particella si trova all’origine e in un intervallo di tempo di 2ns percorre una distanza di 25cm.
Una navicella passa con velocità v=0,80c lungo la direzione x del laboratorio, nel verso positivo, e da essa si osserva il moto della stessa particella.
Determinare le velocità medie della particella nei due sistemi di riferimento.
Quale intervallo di tempo e quale distanza misurerebbe un osservatore posto sulla navicella?
Prerequisiti
conoscenza delle trasformazioni di Lorentz
addizione delle velocità
Sviluppo
Nel primo sistema di riferimento al velocità media sarà:
Nel secondo sistema di riferimento devo applicare la relazione:
dal sistema della navetta osserverò una contrazione delle lunghezze:
ossia
L’intervallo di tempo sarà:
quindi rispetto al sistema di riferimento della navicella vi è stata una contrazione delle lunghezze ed una dilatazione dei tempi.
Spiegare la relazione esistente tra la variazione del campo che induce la corrente e il verso della corrente indotta. Calcolare la corrente media che passa nella spira durante i seguenti intervalli di tempo:
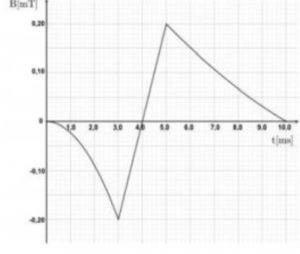
Una spira di rame, di resistenza racchiude un’area di ed è immersa in un campo magnetico uniforme, le cui linee di forza sono perpendicolari alla superficie della spira. La component del campo magnetico perpendicolare alla superficie varia nel tempo come indicato in figura.
a: da 0,0 ms a 3,0 ms
b: da 3,0 ms a 5,0 ms
c: da 5,0 ms a 10 ms
Prerequiti
Conoscenza legge di Faraday-Neumann
Sviluppo
La corrente
l’unica cosa che varia nel tempo è il campo indizione magnetico secondo il grafico, la superficie rimane costante per cui si avrà:
quindi finchè il campo magnetico è negativo si avrà la corrente da un verso appena diventa positivo la corrente avrà verso opposto.
Per calcolare il valore medio della corrente tra i ari intervalli di deve calcolare il valore del campo magnetico in tali intervalli estrapolando i dati.
Intervallo [ms]
Campo magnetico B [mT]
0-3
3-5
5-10
Le funzioni trovate sono: nel primo tratto una parabola con vertice nell’origine e passante per il punto negli altri due casi sono delle rette che passano per i punti estratti dal grafico.
Per trovare il valore medio della corrente nei vari intervalli si deve svolgere il seguente integrale:
Intervallo
Integrale
0-3
3-5
5-10
Primo intervallo:
per il secondo ed il terzo è sufficiente sostituire i valori.

 definita da:
definita da:

 il cui grafico passa per l’origine.
il cui grafico passa per l’origine.  individuandone eventuali simmetrie, asintoti, estremi.
individuandone eventuali simmetrie, asintoti, estremi.





 quindi è simmetrica rispetto l’asse x.
quindi è simmetrica rispetto l’asse x.

 che è proprio il punto di massimo osservando il segno della derivata prima.
che è proprio il punto di massimo osservando il segno della derivata prima.









 dato in precedenza e calcolo il valore dell’integrale:
dato in precedenza e calcolo il valore dell’integrale:

 significa che anche il flusso è nullo per cui nell’integrale precedente quando t=0 anche il flusso è nullo per cui:
significa che anche il flusso è nullo per cui nell’integrale precedente quando t=0 anche il flusso è nullo per cui:





 con
con 
 e
e  sono costanti positive e
sono costanti positive e  è il tempo trascorso dall’istante iniziale, espresso in secondi (s).
è il tempo trascorso dall’istante iniziale, espresso in secondi (s).![[T]=k\cfrac{[s][m]}{\sqrt{([s]^2)^3}}](https://www.whymatematica.com/wp-content/ql-cache/quicklatex.com-78c527c07cae815fd46483f078dcf60c_l3.png "Rendered by QuickLaTeX.com")
![k=\cfrac{[T][s]^2}{[m]}](https://www.whymatematica.com/wp-content/ql-cache/quicklatex.com-9341953ae05e6fd1fc037540c21ed0c7_l3.png "Rendered by QuickLaTeX.com")

 perpendicolare alla regione S. Facendo ruotare la spira intorno all’asse x con velocità angolare ω costante, in essa si genera una corrente indotta la cui intensità massima è pari a 5,0mA. Determinare il valore di ω.
perpendicolare alla regione S. Facendo ruotare la spira intorno all’asse x con velocità angolare ω costante, in essa si genera una corrente indotta la cui intensità massima è pari a 5,0mA. Determinare il valore di ω.

 ed è l’unico termine che varia con il tempo per cui la sua derivata risulta:
ed è l’unico termine che varia con il tempo per cui la sua derivata risulta:


 ;
;  e
e 
 ,
,  e
e  . Il verso di
. Il verso di  è indicato in figura mentre gli altri due versi non sono indicati.
è indicato in figura mentre gli altri due versi non sono indicati.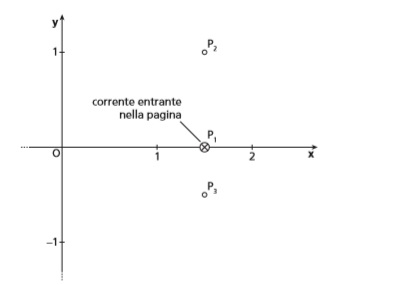

 è posizionato più in basso rispetto alla curva
è posizionato più in basso rispetto alla curva  ma verifico che sia più in alto della curva
ma verifico che sia più in alto della curva  per cui
per cui  è posizionato più in alto rispetto alla curva
è posizionato più in alto rispetto alla curva  per cui
per cui  è posizionato più in basso rispetto alla curva
è posizionato più in basso rispetto alla curva  per cui
per cui 
 e
e  .
.  ossia ponendo
ossia ponendo  risulta -1.
risulta -1. ossia ponendo
ossia ponendo  e risolvendo l’equazione di secondo grado
e risolvendo l’equazione di secondo grado  sono:
sono: e
e





 e massimo
e massimo 



 e guardando solo i termini che non sono nell’esponente si ha la condizione
e guardando solo i termini che non sono nell’esponente si ha la condizione  ossia
ossia  .
. è quello di simmetria. Come si poteva anche vedere dal grafico
è quello di simmetria. Come si poteva anche vedere dal grafico

 che ha come soluzioni 0 e 2
che ha come soluzioni 0 e 2 che ha come soluzione o e 2.
che ha come soluzione o e 2. e in
e in  .
.





 .
.

 in
in  , la funzione g ammette un massimo e un minimo assoluti. Determinare i valori di a e b in corrispondenza dei quali i grafici delle due funzioni f e g si intersecano nel punto A(2,1).
, la funzione g ammette un massimo e un minimo assoluti. Determinare i valori di a e b in corrispondenza dei quali i grafici delle due funzioni f e g si intersecano nel punto A(2,1).  .
.








 .
. , ottenuta dalla composizione di un moto circolare uniforme di raggio r=10.5 cm e di un moto rettilineo uniforme. Determinare il modulo del vettore velocità e l’angolo che esso forma con
, ottenuta dalla composizione di un moto circolare uniforme di raggio r=10.5 cm e di un moto rettilineo uniforme. Determinare il modulo del vettore velocità e l’angolo che esso forma con 









 .
.





 racchiude un’area di
racchiude un’area di  ed è immersa in un campo magnetico uniforme, le cui linee di forza sono perpendicolari alla superficie della spira. La component del campo magnetico perpendicolare alla superficie varia nel tempo come indicato in figura.
ed è immersa in un campo magnetico uniforme, le cui linee di forza sono perpendicolari alla superficie della spira. La component del campo magnetico perpendicolare alla superficie varia nel tempo come indicato in figura.





 negli altri due casi sono delle rette che passano per i punti estratti dal grafico.
negli altri due casi sono delle rette che passano per i punti estratti dal grafico.


