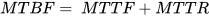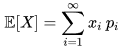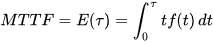La tolleranza ai guasti (o fault-tolerance, dall’inglese) è la capacità di un sistema di non subire avarie (cioè interruzioni di servizio) anche in presenza di guasti. La tolleranza ai guasti è uno degli aspetti che costituiscono l’affidabilità. È importante notare che la tolleranza ai guasti non garantisce l’immunità da tutti i guasti, ma solo che i guasti per cui è stata progettata una protezione non causino fallimenti.
Robustezza
La robustezza è la proprietà di quei sistemi che assicurano una rapida rilevazione degli errori e che ne consentono il confinamento.
Studi statistici hanno mostrato che almeno due errori su tre sono dovuti a richieste illegali di operazioni su oggetti, cioè proprio a quelle richieste che i controlli di protezione prevengono.
Misurazioni della tolleranza ai guasti
Una tipica misurazione della tolleranza ai guasti è costituita dal calcolare il tempo medio che intercorre tra due fallimenti del sistema (in inglese Mean Time Between Failures, MTBF).
Tempo medio fra i guasti
Il tempo medio fra i guasti (in inglese mean time between failures, spesso abbreviato in MTBF), è un parametro di affidabilità applicabile a dispositivi meccanici, elettrici ed elettronici e ad applicazioni software.
Il MTBF è il valore medio tra un guasto ed il successivo; la sua misura ha importanza in moltissimi ambiti; ad esempio:
la valutazione della vita media di un dispositivo elettronico, o di un componente meccanico, nell’ambito della progettazione
la valutazione del tempo di attesa in coda di un semilavorato, se il guasto è riferito ad una macchina utensile in un processo di produzione industriale
Per MTBF (Mean Time Between Failures) si intende la somma di due tempi: MTTF (Mean Time To Failure) e MTTR (Mean Time To Repair).
In generale MTTF è definito come il valore atteso della funzione di distribuzione statistica dei guasti.
calcolare il valore atteso di variabili aleatorie discrete
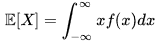
Calcolare il valore atteso di variabili aleatorie assolutamente continue
Nel caso in cui la distribuzione dei guasti sia di tipo esponenziale come la variabile casuale esponenziale negativa, ossia è caratterizzata da tasso di guasto lambda
costante nel tempo, allora in termini matematici il MTTF è semplicemente il reciproco del tasso di guasto
Parlare di RAID significa parlare di continuità di servizio, significa cercare di limitare gli INEVITABILI malfunzionamenti di un sistema a causa del normale ciclo di vita dei componenti. RAID è acronimo di Redundant Array of Independent Disks.
La tecnologia RAID nasce per effettuare la copia o il controllo degli errori degli hard disk presenti in un host o in un server. A seconda del tipo di controllo o di ridondanza si parla di varie tipologie di RAID.
Le modalità più diffuse sono RAID 0, 1, 5 e 10. La 3 e la 4 sono state praticamente soppiantate dalla 5. Alcuni sistemi usano modalità nidificate come la 10 o altre modalità proprietarie.
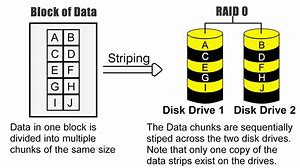
RAID 0
Divide i dati equamente tra due o più dischi, tipicamente tramite sezionamento (o striping), ma senza mantenere alcuna informazione di parità o ridondanza che aumenti l’affidabilità (la dicitura RAID, ancorché diffusa, è pertanto impropria). RAID 0 è usato generalmente per aumentare le prestazioni di un sistema, o per la comodità di usare un grande numero di piccoli dischi fisici come se fossero un piccolo numero di grandi dischi virtuali.
Vantaggi costo di implementazione basso; alte prestazioni in scrittura e lettura, grazie al parallelismo delle operazioni I/O dei dischi concatenati.
Svantaggi impossibilità d’utilizzo di dischi hot-spare (il disco hot-spare viene lasciato dormiente fino al momento di un guasto degli altri dischi) ; affidabilità drasticamente ridotta, anche rispetto a quella di un disco singolo.
FONDAMENTALE
Raid 0 significa che i dati vengono sezionati e scritti su dischi diversi. La rottura del disco farà sì che i dati presenti in quel disco si perdano mentre rimangono quelli dell’altro disco.
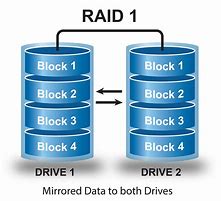
RAID 1
detta anche mirror, mantiene una copia esatta di tutti i dati su almeno due dischi.
È utile quando la ridondanza sia ritenuta un’esigenza più importante rispetto allo sfruttamento ottimale della capacità di memorizzazione dei dischi.
L’insieme, infatti, limita il suo volume a quello del disco di taglia inferiore. D’altro canto, visto che un sistema con n dischi è in grado di resistere alla rottura di n-( “n”-1 ) componenti, l’affidabilità aumenta linearmente al numero di dischi presenti.
A livello prestazionale, il sistema RAID 1 aumenta tipicamente i risultati per le operazioni di lettura, perché molte implementazioni sono in grado di effettuare diverse operazioni in parallelo: mentre la lettura di un blocco è ancora in corso su un disco, cioè, possono effettuarne un’altra su un disco diverso.
In ogni caso, la velocità di lettura raggiunge quella del disco più veloce in presenza di dispositivi di memorizzazione con prestazioni diverse: una singola operazione di lettura è richiesta inizialmente e contemporaneamente su tutti i dischi, ma si conclude nel momento della prima risposta ricevuta.
Viceversa, la velocità di scrittura scende a quella del disco più lento, perché questo tipo di azione richiede il compimento della replica della stessa operazione su ogni disco dell’insieme.
Vantaggi affidabilità, cioè resistenza ai guasti, che aumenta linearmente con il numero di copie; velocità di lettura (in certe implementazioni e sotto certe condizioni).
Svantaggi bassa scalabilità; costi aumentati linearmente con il numero di copie; velocità di scrittura ridotta a quella del disco più lento dell’insieme.
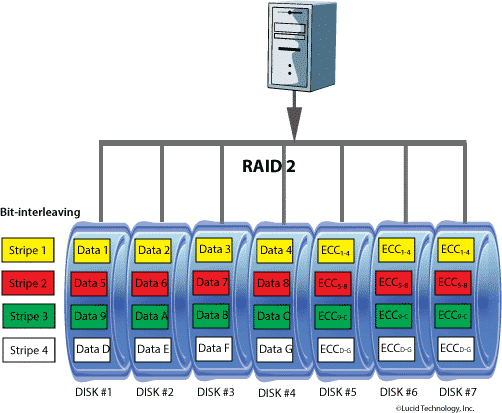
RAID 2
Divide i dati al livello di bit (invece che di blocco) e usa un codice di Hamming per la correzione d’errore che permette di correggere errori su singoli bit e di rilevare errori doppi.
Questi dischi sono sincronizzati dal controllore, in modo tale che la testina di ciascun disco sia nella stessa posizione in ogni disco. Questo sistema si rivela molto efficiente in ambienti in cui si verificano numerosi errori di lettura o scrittura, ma in ambienti più prestanti, data l’elevata affidabilità dei dischi, il RAID 2 non viene utilizzato
Si notino quindi la presenza di sette dischi esattamente come il codice di Hamming (7,4) studiato. Con stripe si intende il singolo bit.
Il numero minimo di dischi è 7.
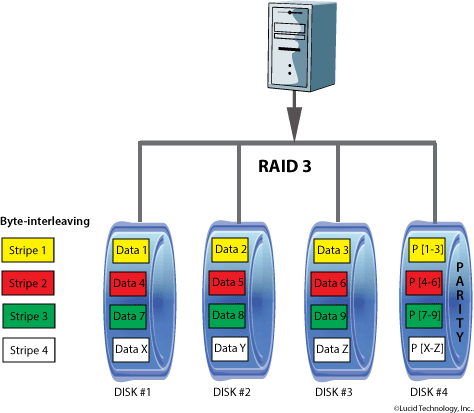
RAID 3
Usa una divisione al livello di byte con un disco dedicato alla parità.
Il RAID-3 è estremamente raro nella pratica.
Uno degli effetti collaterali del RAID-3 è che non può eseguire richieste multiple simultaneamente. Questo perché ogni singolo blocco di dati ha la propria definizione diffusa tra tutti i dischi del RAID e risiederà nella stessa posizione, così ogni operazione di I/O richiede di usare tutti i dischi.
Con stripe si intende un byte. Il byte è generato nella fase di scrittura, memorizzato nel disco di parità e ricontrollato in fase di lettura.
Il numero minimo di dischi è 3: utilizza un minimo di due dischi per i dati, più un disco dedicato alla memorizzazione dei Byte di parità.
Le prestazioni in scrittura peggiorano, poiché per ogni operazione eseguita sui dati necessita del calcolo della parità, da scrivere sul disco dedicato a questa funzione. Inoltre, poiché il disco dedicato alla parità è unico, questo costituisce anche una specie di collo di bottiglia che può limitare ulteriormente le prestazioni in scrittura (infatti mentre i dati sono scritti su vari dischi, la parità viene scritta, per ogni operazione di scrittura, sempre sullo stesso disco). Per assurdo, aumentando i dischi, le prestazioni in lettura migliorano e quelle in scrittura possono addirittura peggiorare.
In caso di guasto, si accede al disco di parità e i dati vengono ricostruiti.
Una volta che il disco guasto viene rimpiazzato, i dati mancanti possono essere ripristinati e l’operazione può riprendere. La ricostruzione dei dati è piuttosto semplice. Si consideri un array di 5 dischi nel quale i dati sono contenuti nei dischi X0, X1, X2 e X3 mentre X4 rappresenta il disco di parità.
La parità per l’i-esimo bit viene calcolata come segue:
X4(i) = X3(i) ⊕ X2(i) ⊕ X1(i) ⊕ X0(i)
Si supponga che il guasto interessi X1.
Se eseguiamo l’OR esclusivo di X4(i) ⊕ X1(i) con entrambi i membri della precedente equazione otteniamo: X1(i) = X4(i) ⊕ X3(i) ⊕ X2(i) ⊕ X0(i)
Così, i contenuti della striscia di dati su X1 possono essere ripristinati dai contenuti delle strisce corrispondenti sugli altri dischi dell’array.
Questo principio persiste nei livelli RAID superiori.
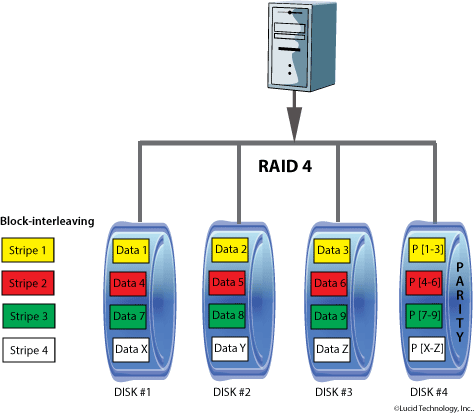
RAID 4
Usa una divisione dei dati a livello di blocchi e mantiene su uno dei dischi i valori di parità, in maniera molto simile al RAID 3, dove la suddivisione è a livello di byte. Questo permette ad ogni disco appartenente al sistema di operare in maniera indipendente quando è richiesto un singolo blocco.
Se il controllore del disco lo permette, un sistema RAID 4 può servire diverse richieste di lettura contemporaneamente. In lettura la capacità di trasferimento è paragonabile al RAID 0, ma la scrittura è penalizzata, perché la scrittura di ogni blocco comporta anche la lettura del valore di parità corrispondente e il suo aggiornamento.
Il RAID 4 utilizza la tecnica dello striping e per la sicurezza utilizza la tecnica del controllo di parità. E’ in pratica la stessa configurazione del RAID 3, con la differenza che lo striping viene eseguito a livello di blocchi e non di singoli Byte. Allo stesso modo il calcolo della parità viene eseguito a livello di blocco e scritto di conseguenza.
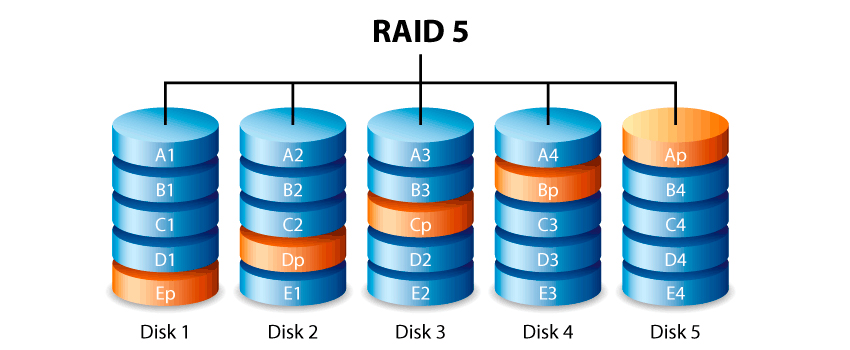
RAID 5
Un sistema RAID 5 usa una suddivisione dei dati a livello di blocco, distribuendo i dati di parità uniformemente tra tutti i dischi che lo compongono. È una delle implementazioni più popolari, sia in software, sia in hardware, dove praticamente ogni dispositivo integrato di storage dispone del RAID-5 tra le sue opzioni.
La differenza fondamentale, che lo distingue dal RAID 4, è che in questa configurazione non esiste il disco dedicato alla scrittura della parità, ma su tutti i dischi vengono scritti indifferentemente i dati o il corrispondente calcolo di parità. N.B.: la parità viene comunque scritta su disco diverso da quello dei dati, altrimenti il checksum non avrebbe senso; in pratica il blocco di parità viene trattato come un blocco dati qualsiasi e distribuito su un disco qualsiasi. Non si ha vantaggio in termini di spazio occupato dalla parità, in quanto lo spazio totale “sottratto” ai dati risulta essere sempre l’equivalente di un disco, ma si ottiene un miglioramento delle prestazioni in fase di scrittura eliminando il percorso obbligato, su unico disco, per la scrittura della parità. Per questo motivo è forse la più popolare delle configurazioni RAID in striping, tenendo anche conto che alcune MB avanzate implementano controller con il supporto RAID 5.
Per la ricostruzione dei dati in caso di guasto del disco, valgono le stesse considerazioni del RAID 3.
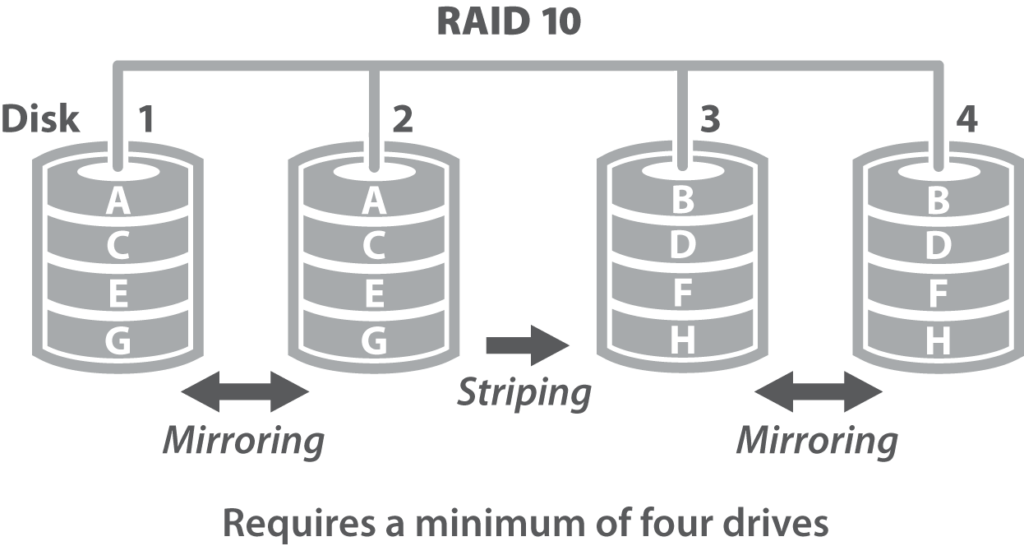
RAID 10
Un sistema RAID 1+0, chiamato anche RAID 10 i livelli RAID sono usati in senso invertito.
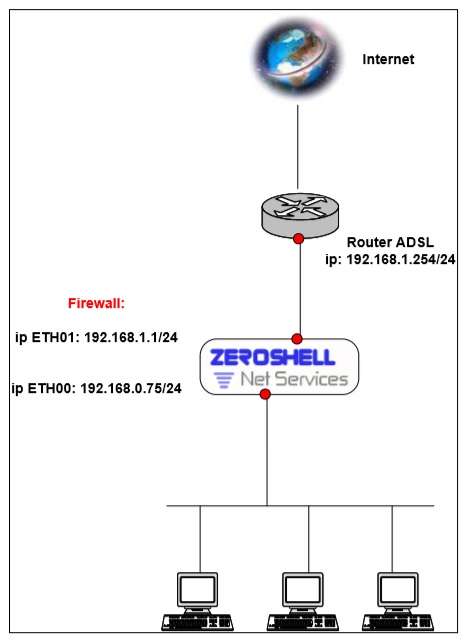
Tale configurazione non permette la possibilità di connettersi in ssh o con l’interfaccia web con Zeroshell in quanto esso risponde all’indirizzo 192.168.0.75.
Quindi ho modificato:
address 192.168.0.1
network 192.0.0.0 broadcast 192.0.0.255
Quindi ho modificato il file dnsmasq nella seguente maniera:
nano /etc/dnsmasq.conf
interface=eth0 # Use interface eth0
listen-address=192.168.0.1 # Specify the address to listen on
bind-interfaces # Bind to the interface
server=208.67.222.222 # Use OpenDNS
domain-needed # Don’t forward short names
bogus-priv # Drop the non-routed address spaces.
dhcp-range=192.168.0.10,192.168.0.50,12h # IP range and lease time
tutto il resto della configurazione rimane invariata.
Per installare Zeroshell ho scaricato l’ultima versione dal sito:
Poi salvando il file .gz lo scompatto attraverso Winzip se sono sotto Windows.
a questo punto utlizzo w32diskimager per copiare l0immagine nella mia microsd da cui partirà il sistema operativo.
Quindi collego il raspberry nel quale ho installato Zeroshell.
E dal browser del raspberry o da un qualunque host collegato alla rete il cui server è il raspberry stesso posso digitare sul browser:
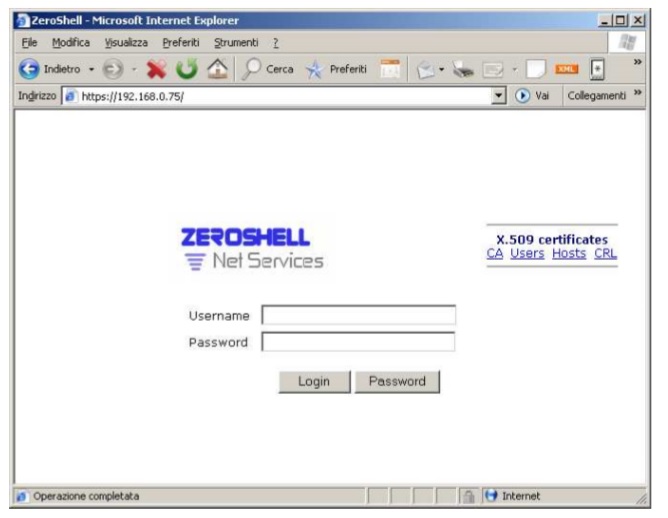
https://192.168.0.75 e comparirà la seguente schermata:
login admin
password zeroshell
Per poter permettere di accedere ad internet bisogna impostare il default gateway:
Si accede al Raspberry in cui è installato Zeroshell, si selezione
<I> IP manager
<G> Set Default Gateway
Si inserisce l’indirizzo IP presente nel Raspberry o Router che fa da gateway
Per usare la scheda wifi del raspberry bisogna seguire i seguenti passi:
<W> wifi manager
<N> new subsystemID
invio lasciando il nome di default
<1> Access Point
SSID dare il nome che si vuole alla rete wifi che comparirà nell’elenco delle wifi.
Hide ssid mettere no
per adesso scelgo di non usare la crittografia e lasciare la rete libera.
Attivare ssh per accedere al pannello di controllo
Si entra tramite il browser: https://192.168.0.75
quindi setup e scegliere il menù ssh, attivarlo e salvarlo.
Basta quindi aprire una sessione ssh:
ssh admin@192.168.0.75 e dopo aver immesso la password si è nel sistema.
Creare il bridge tra la WLAN00 e ETH0
sempre dal browser di va su setup e su network, impostare bridge scegliendo le due componenti precedenti.
Attivare il captive portal
Si va su CaptivePortal e si sceglie come interfaccia WLAN00.
Attivare dhcp
Sempre utilizzando l’interfaccia grafica si va su dhcp e si seleziona il bridge precedentemente scelto e come default gateway mettere quello impostato precedentemente (192.168.0.1) ad esempio
Installare Zeroshell in una rete comporta vari benefici:
Bilanciamento e Failover di connessioni multiple a Internet;
Connessioni UMTS/HSDPA mediante modem 3G;
Server RADIUS per fornire autenticazione e gestione automatica delle chiavi di cifratura alle reti Wireless 802.11b, 802.11g e 802.11a supportando il protocollo 802.1x nella forma EAP-TLS, EAP-TTLS e PEAP; sono supportate le modalità WPA con TKIP e WPA2 con CCMP conforme allo standard 802.11i; il server RADIUS può inoltre, in base allo username, il gruppo di appartenenza o MAC Address del supplicant smistare l’accesso su di una VLAN 802.1Q assegnata ad un SSID;
Captive Portal per il supporto del web login su reti wireless e wired. Zeroshell agisce da gateway per la rete su cui è attivo il Captive Portal e su cui gli indirizzi IP (di solito appartenenti a classi private) vengono forniti dinamicamente dal DHCP. Un client che accede a questa network privata deve autenticarsi mediante un web browser con username e password Kerberos 5 prima che il firewall di Zeroshell gli permetta di accedere alla LAN pubblica. I gateway Captive Portal sono utilizzati spesso per fornire accesso a Internet negli HotSpot in alternativa all’autenticazione 802.1X troppo complicata da configurare per gli utenti. Zeroshell implementa la funzionalità di Captive Portal in maniera nativa, senza utilizzare altro software specifico come NoCat o Chillispot;
Gestione del QoS (Quality of Service) e traffic shaping per il controllo del traffico su reti congestionate. Si possono imporre vincoli sulla banda minima garantita, sulla banda massima e sulla priorità di un pacchetto (utile nelle connessioni realtime come le VoIP). Tali vincoli potranno essere applicati sulle interfacce Ethernet, sulle VPN, sui point to point PPPoE, sui bridge e sui bonding (aggregati) di VPN. La classificazione del traffico può avvenire anche mediante i filtri Layer 7 che permettono il Deep Packet Inspection (DPI) e quindi di regolare la banda e la priorità da assegnare ai flussi di applicazioni come VoIP e P2P;
HTTP Proxy con antivirus open source ClamAV in grado di bloccare in maniera centralizzata le pagine web contenenti Virus. Il proxy, realizzato con HAVP, potrà funziona in modalità transparent proxy, intendendo con ciò, che non è necessario configurare i web browser degli utenti per utilizzare il server proxy, ma, le richieste http verranno automaticamente reindirizzate a quest’ultimo. È ovvio, che in questo caso, la macchina che fa da proxy deve essere anche un gateway (router IP o bridge);
Supporto per la funzionalità di Wireless Access Point con Multi SSID utilizzando schede di rete WiFi basate sui chipset Atheros. In altre parole, un box Zeroshell con una di tali schede WI-FI può funzionare come Access Point per le reti IEEE 802.11 supportando i protocolli 802.1X, WPA per l’autenticazione e la generazione di chiavi dinamiche. Ovviamente l’autenticazione avviene tramite EAP-TLS o PEAP sfruttando il server RADIUS integrato;
VPN host-to-lan con protocollo L2TP/IPsec in cui L2TP (Layer 2 Tunneling Protocol) autenticato con username e password Kerberos v5 viene incapsulato all’interno di IPsec autenticato mediante IKE con certificati X.509;
VPN lan-to-lan con incapsulamento delle trame Ethernet in tunnel SSL/TLS, con supporto per VLAN 802.1Q e aggregabili in load balancing (incremento di banda) o fault tollerance (incremento di affidabilità);
Router con route statiche e dinamiche (RIPv2 con autenticazione MD5 o plain text e algoritmi Split Horizon e Poisoned Reverse);
Bridge 802.1d con protocollo Spanning Tree per evitare loop anche in presenza di percorsi ridondati;
Firewall Packet Filter e Stateful Packet Inspection (SPI) con filtri applicabili sia in routing sia in bridging su tutti i tipi di interfaccia di rete comprese le VPN e le VLAN;
Controllo mediante Firewall e Classificatore QoS del traffico di tipo File sharing P2P;
NAT per utilizzare sulla LAN indirizzi di classi private mascherandoli sulla WAN con indirizzi pubblici;
TCP/UDP port forwarding (PAT) per creare Virtual Server, ovvero cluster di server reali visti con un unico indirizzo IP (l’indirizzo del Virtual Server). Le richieste sul server virtuale saranno smistate sui server reali in Round-Robin (ciclicamente) preservando le connessioni e le sessioni già esistenti. Si può così ottenere il load balancing su web farm, cluster SQL e farm di calcolo;
Server DNS multizona e con gestione automatica della Reverse Resolution in-addr.arpa;
Server DHCP multi subnet con possibilità di assegnare l’indirizzo IP in base al MAC Address del richiedente;
Virtual LAN 802.1Q (tagged VLAN) applicabili sulle interfacce Ethernet, sulle VPN lan-to-lan, sui bonding di VPN e sui bridge composti da interfacce Ethernet, VPN e bond di VPN;
Client PPPoE per la connessione alla WAN tramite linee ADSL, DSL e cavo (richiede MODEM adeguato);
Client DNS dinamico che permette la rintracciabilità su WAN anche quando l’IP è dinamico. Gestione dinamica del record dns MX per l’instradamento SMTP della posta elettronica su mail server con IP variabile;
Server e client NTP (Network Time Protocol) per mantenere gli orologi degli host sincronizzati;
Server syslog per la ricezione e la catalogazione dei log di sistema prodotti da host remoti quali sistemi Unix, router, switch, access point WI-FI, stampanti di rete e altro compatibile con protocollo syslog;
Autenticazione Kerberos 5 mediante un KDC integrato e cross autenticazione tra domini;
Autorizzazione LDAP, NIS e RADIUS;
Autorità di certificazione X.509 per l’emissione e la gestione di certificati elettronici;
Integrazione tra sistemi Unix e domini Windows Active Directory in un unico sistema di autenticazione e autorizzazione mediante LDAP e Kerberos 5 cross realm authentication.
Confidenzialità, Integrità e Disponibilità che rappresentano i tre elementi cardine che la sicurezza in ambito IT mira a garantire per quanto concerne i dati.
L’obiettivo dell’utilizzo di una VPN (Virtual Private Network – Rete Private Virtuale) è quello di assicurare, fra le altre cose, almeno due degli elementi della triade: la confidenzialità e l’integrità dei dati in transito.
Quando due entità o due utenti necessitano di dialogare fra loro attraverso una qualsiasi rete, ed in particolar modo su Internet, è possibile stabilire fra di essi un canale virtuale, e fare in modo che all’interno di questo canale “dedicato” i dati transitino in maniera sicura. Pensiamo proprio alla rete Internet e a due persone che devono interloquire fra loro attraverso la rete pubblica: nulla e nessuno potrà garantire che ciò che esse si comunicano non venga intercettato o copiato a loro insaputa, in questo caso vengono in aiuto le VPN. La P di “private” sta ad indicare la privatezza ossia la confidenzialità (e integrità) delle informazioni mentre la V di “virtual” indica il fatto che il canale è solo logicamente instaurato fra i due estremi, senza la necessità di ricorrere a costose linee dedicate. Le VPN, quindi, rispetto alle linee dedicate offrono pertanto due vantaggi essenziali che sono quelli dell’economicità (evitando l’acquisto di linee dedicate appunto) e la scalabilità (n utenti che debbano collegarsi ad uno stesso punto – ad esempio la sede aziendale – sfrutteranno tutti il medesimo canale di accesso, ossia la Internet, ovunque essi si trovino). Le componenti di confidenzialità e integrità offerte dalle VPN si basano essenzialmente sull’utilizzo della crittografia, gli algoritmi crittografici permettono infatti da un lato di rendere intelleggibile ad un eventuale “eavesdropper” il flusso dei dati fra i due capi della VPN e dall’altro garantiscono che quanto viene trasmesso non sia stato in alcun modo manipolato o danneggiato (intenzionalmente o meno).
In maniera molto semplicistica, della parte di confidenzialità si occupano gli algoritmi di cifratura (sia a chiave segreta che a chiave pubblica), mentre per l’aspetto dell’integrità ci si rivolge agli algoritmi di “hashing“.
Protocolli, tecnologie e tipologie di VPN
In questo contributo vorrei concentrarmi essenzialmente su due tipi di VPN:
VPN di accesso remoto
VPN site-to-site
Esistono poi due differenti tecnologie, ciascuna delle quali opera a differenti livello della pila ISO-OSI:
VPN IPsec
VPN SSL
A onor del vero questa classificazione è veramente riduttiva seppure – in ottica sicurezza – racchiuda i gruppi e i protocolli fondamentali, in letteratura probabilmente troverete tassonomie molto più estese perché sarebbe possibile parlare di altri tipi ed altre classificazioni delle VPN. Solo per fare un esempio è doveroso accennare alle cosiddette VPN MPLS che in ambito aziendale sono largamente diffuse, ma volendoci concentrare sull’aspetto della sicurezza e considerando il fatto che, di default, le VPN MPLS non forniscono la crittografia dei dati preferisco escluderle dal presente contributo.
Le VPN per l’accesso remoto
Vengono utilizzate nei casi in cui un utente in mobilità, in qualsiasi luogo del globo, debba collegarsi ad una sito remoto (tipicamente una sede aziendale) e desideri farlo in sicurezza, al riparo da intercettazioni. La costruzione del canale virtuale fra l’utente remoto e la sede aziendale, oltre a mettere al sicuro l’utente e l’azienda, permette di estendere la rete aziendale al di fuori dei propri confini geografici rendendo l’utente finale in grado di accedere a risorse interne (file, applicazioni, server, ecc.) altrimenti inaccessibili. Questo tipo di VPN possono basarsi sia sullo standard IPsec che sui protocolli della famiglia SSL (evoluti in TLS).
Le VPN site-to-site
Vengono utilizzate quando sedi o filiali della stessa azienda o di aziende differenti, situate a distanza geografica, hanno necessità di instaurare un canale di comunicazione sicuro (e molto spesso permanente) sfruttando un canale non sicuro come può essere Internet. Tali VPN sfruttano tipicamente lo standard IPsec e vengono realizzate solitamente tramite specifici terminatori delle VPN (router, firewall, server o appliance) a un capo e all’altro del canale. Una volta stabilita la VPN le due entità/organizzazioni entreranno in contatto potendo condividere in maniera sicura i dati che intendono scambiare fra loro (file, flussi, applicazioni, ecc.) senza dover acquistare da un provider una costosa linea dedicata.
Non è certo infrequente, nella realtà aziendale di oggi, trovarsi dinanzi a scenari in cui entrambi i tipi di VPN e entrambe le tecnologie (IPsec e SSL) vengono utilizzati allo stesso tempo
La crittografia alla base delle VPN
Entrare nei dettagli di come gli algoritmi di cifratura contribuiscano a realizzare le VPN e a renderle sicure va al di là dello scopo di questo articolo, tuttavia, come già accennato, la crittografia (sia simmetrica che asimmetrica) ricopre l’importante ruolo di abilitatore della confidenzialità e integrità dei dati, ma può entrare in gioco anche in un altro importante aspetto delle VPN: l’autenticazione, qualora quest’ultima faccia uso della crittografia a chiave pubblica, mediante firma digitale RSA.
Ciò che è doveroso specificare è che diversi algoritmi di cifratura (ed in diverse fasi della “vita” di una VPN) entrano in gioco. Gli algoritmi asimmetrici (esempio: RSA e Diffie-Hellman), più onerosi dal punto di vista computazionale, vengono utilizzati per l’autenticazione (RSA) o per lo scambio di chiavi segrete utilizzando un canale insicuro (Diffie-Hellman), mentre gli algoritmi simmetrici (più leggeri e performanti dal punto vista computazionale come 3DES e AES vengono utilizzati per fare il lavoro di cifratura “continua” dei dati una volta che il canale di comunicazione è stabilito.
Un ultimo fondamentale vantaggio delle VPN è il fatto che offrono protezione “anti replay“ ossia rendono impossibile ad un attaccante intercettare i messaggi in transito ed inserire dei messaggi modificati nel flusso dei dati fra sorgente e destinazione, nel caso ciò dovesse avvenire i messaggi modificati verrebbero scartati.
Le soluzioni di mercato
Site-to-site VPN
Per quanto riguarda le VPN site-to-site, la soluzione più diffusa è quella di demandare la realizzazione del tunnel VPN ad apparati di rete capaci di utilizzare lo standard IPsec (che chiameremo terminatori della VPN), che siano essi router o firewall. Occorrerà quindi accordarsi con la controparte (se si tratta di un’azienda esterna) e scegliere i parametri IPsec in modo che il tunnel si attivi con successo, a quel punto i PC o i server attestati ad un capo o all’altro del tunnel potranno “parlarsi” in maniera “trasparente” e sicura allo stesso tempo, lasciando il lavoro di cifratura e decifratura ai terminatori della VPN. I router e firewall più diffusi al mondo, anche non di livello enterprise, supportano lo standard IPSec e ciò rende possibile la protezione dei dati in transito in maniera abbastanza agevole.
VPN di accesso remoto
Per quanto riguarda le VPN per l’accesso remoto, solitamente basate sul protocollo TLS (erede di SSL), sono presenti sul mercato diverse soluzioni. Ciascun vendor potrà proporre la propria implementazione, ma in sostanza si tratta di definire ed installare quello che viene definito “concentratore” delle VPN il quale – esposto su Internet – raccoglierà, dalla rete della sede centrale, le richieste di accesso (tramite il protocollo SSL/TLS) da parte dei client. Le modalità con cui i client potranno realizzare il tunnel VPN sono in sostanza di tre differenti tipi:
clientless (basata esclusivamente sul browser del dispositivo)
plug-in based (ossia basate su un plug-in del browser che viene installato al momento della prima connessione al concentratore)
client-based (quando è prevista l’installazione di un client software ad hoc)
Ciascuna delle soluzioni ha i suoi pro e i suoi contro: certamente la prima, quella clientless, è quella che può essere utilizzata in qualsiasi luogo e su qualsiasi PC che supporti il protocollo SSL. Ciascun vendor poi “colorerà” la propria soluzione in maniera diversa. La scelta di ciascuna azienda, in base alle proprie necessità, ricadrà sulla sfumatura e la soluzione più appropriate.
La prudenza in mobilità e la protezione dei dati aziendali
Un ultimo accenno va certamente fatto ad un altro utilizzo delle VPN che è di grande utilità per chi viaggia spesso, magari anche all’estero, e che fa sovente uso di accessi wi-fi pubblici, erogati da aeroporti o hotel. In questo caso è consigliabile fare ricorso ad un provider di servizi VPN. Esistono infatti sul mercato fornitori di connettività VPN a cifre abbordabili. In maniera molto semplificata, ciò che si ottiene utilizzando questo tipo di servizi ogniqualvolta ci si trovi a doversi collegare ad Internet da luoghi pubblici o “a rischio” è questo: per prima cosa l’utente si collegherà al proprio provider di servizi VPN, da quel momento in poi ogni connessione verso la rete Internet (che sia verso Google, il proprio portale preferito, la propria casella email via web, ecc.) non avverrà in maniera diretta, sarà il server del provider VPN (del quale dobbiamo avere fiducia, s’intende) a fare da tramite fra l’utente e il server di destinazione. Il computer dell’utente e il server VPN comunicheranno attraverso un tunnel interamente cifrato: in tal modo nessun malintenzionato eavesdropper (nella rete dell’albergo o nelle vicinanze se ci sta collegando in wi-fi) potrà interpretare il traffico generato.
Per verificare le ulteriori grandi possibilità di un Raspberry si può collegare ad esso un lettore e scrivere su un badge con il componente RFID 522.
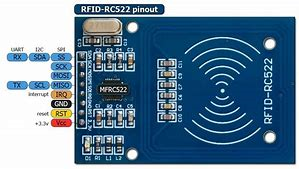
RFID-RC522 è un modulo di lettura di tag RFID. A bassa tensione, a basso costo, la piccola dimensione del chip della carta contact-less lo rendono la scelta migliore per i sistemi di identificazione radio.
RC522 usa tecnologie avanzate di modulazione e demodulazione completamente integrate in tutti i tipi di metodi di comunicazione senza contatto passivo a 13,56 MHz.
Compatibile con i trasponder 14443A. La parte digitale consente di gestire i frames ISO14443A e la rilevazione degli errori, supporta inoltre l’algoritmo di cifratura rapida CRYPTO1. MFRC522 è compatibile con la serie MIFARE contact-less ad alta velocità, a due vie, con velocità di trasmissione dati fino a 424kbit/s.
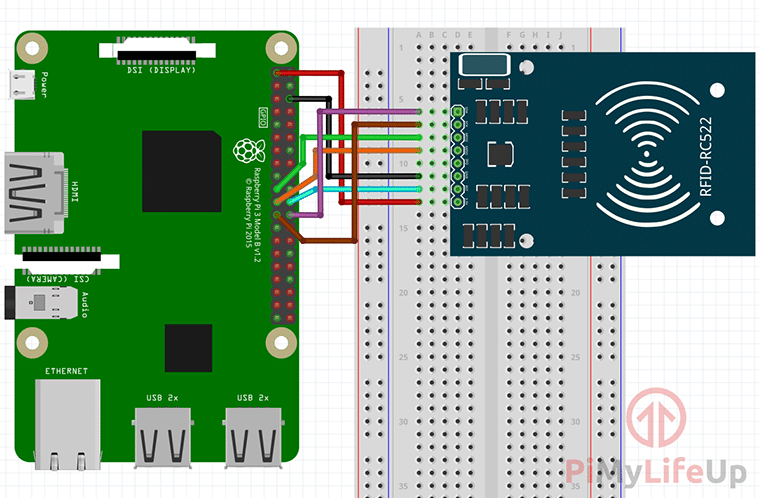
Per prima cosa bisogna collegarlo con il Raspberry con il seguente ordine:
SDA connects to Pin 24.
SCK connects to Pin 23.
MOSI connects to Pin 19.
MISO connects to Pin 21.
GND connects to Pin 6.
RST connects to Pin 22.
3.3v connects to Pin 1.
Adesso bisogna attivare l’interfaccia SPI del Raspberry. Se si vogliono approfondimenti sul tipo di interfaccia consiglio il seguente articolo approfondimenti SPI.
Come root:
raspi-config
Selezionare il punto 5 Interfacing Options e quindi P4 SPI.
Effettuare il reboot del Raspberry.
Quindi come root
apt-get install python2.7-dev python-pip git
successivamente dare il comando
pip install spidev
quindi
pip install mfrc522
creare la libreria in cui inserirò i miei applicativi Python
mkdir ~/pi-rfid
adesso creare il file Write.py
che conterrà:
#!/usr/bin/env python
import RPi.GPIO as GPIO from mfrc522 import SimpleMFRC522
reader = SimpleMFRC522()
try: text = raw_input(‘New data:’) print(“Now place your tag to write”) reader.write(text) print(“Written”) finally: GPIO.cleanup()
Per eseguire il file è sufficiente digitare:
python Write.py
Per leggere RFID si crea il file Read.py contenente le seguenti righe di codice:
#!/usr/bin/env python
import RPi.GPIO as GPIO from mfrc522 import SimpleMFRC522
reader = SimpleMFRC522()
try: id, text = reader.read() print(id) print(text) finally: GPIO.cleanup()
Gli errori di trasmissione sono normalmente dovuti alla presenza di disturbi del canale di comunicazione che impediscono la corretta ricezione dei dati trasmessi. Le sorgenti di segnali magnetici ed elettrici che un’onda elettromagnetica incontra durante la sua propagazione possono infatti modificarne le proprietà. Può accadere quindi che dei bit “0” vengano trasformati in “1” e viceversa.
A questo proposito si può riprendere la trattazione iniziale sul controllo degli errori.
Classificazione degli errori
Gli errori che possono verificarsi durante la comunicazione sono di tre tipi [HOL91]:
Errori single-bit (a bit singolo): coinvolgono un solo bit dell’unità dati (per esempio un byte) il cui valore viene trasformato da “0” a “1” o viceversa. Questo tipo di errore è il più comune.
Esempio di errore single-bit
Errori multiple-bit (a bit multiplo): coinvolgono due o più bit non consecutivi dell’unità dati, il cui valore viene trasformato da “0” a “1” o viceversa . Questo tipo di errore è abbastanza comune.
Esempio di errore multiple-bit
Errori burst (a raffica): coinvolgono due o più bit consecutivi dell’unità dati, il cui valore viene trasformato da “0” a “1” o viceversa Questo tipo di errore è il meno comune.
Esempio di errore burst
Tecniche di rilevamento degli errori
Un metodo molto semplice per l’individuazione degli errori è quello di attuare un doppio invio per ogni unità di dati. Il ricevente ha quindi il compito di confrontare bit per bit le due copie della stessa unità. Questa tecnica renderebbe la trasmissione perfettamente affidabile, essendo infinitesima la probabilità di due errori sullo stesso bit, ma molto lenta. Il tempo di trasmissione verrebbe più che duplicato poiché alla durata della doppia trasmissione, infatti, andrebbe aggiunto il tempo necessario alla verifica da parte del ricevente. Si preferiscono quindi altri metodi che si basano sull’aggiunta di pochi bit scelti in modo sapiente. La tecnica che viene utilizzata da questi metodi è nota come ridondanza : i bit supplementari, infatti, sono a tutti gli effetti ridondanti e vengono distrutti non appena il sistema ricevente si sia accertato di una trasmissione corretta [HOL91].
Rilevamento degli errori con tecnica di ridondanza
VRC (Vertical Redundancy Check) Il VRC è il metodo più comune per il controllo d’errore: viene aggiunto un singolo bit supplementare all’unità dati in modo che il numero di bit uguali a “1” dell’intera unità, bit supplementare compreso, diventi pari o dispari. Nel primo caso si parla di parity check o controllo di parità ; nel secondo caso si parla di controllo di disparità.
Controllo di parità
L’algoritmo VRC è molto facile da implementare ma ha diversi limiti; se infatti una unità ha un numero pari di bit invertiti, si ha una compensazione dell’errore, che quindi non viene rilevato [DES03]. LRC (Longitudinal Redundancy Check) L’algoritmo LRC è una sorta di VCR bidimensionale. Come nel VCR si ha infatti l’aggiunta del bit di parità ad ogni unità dati. Ad ogni blocco viene però aggiunta una unità supplementare che contiene i bit di parità associati alle sequenze di bit corrispondenti del blocco
Algoritmo LRC
L’algoritmo LRC assicura maggiore affidabilità nell’individuazione degli errori di tipo multiple-bit e burst, ma ha ancora dei limiti poiché può essere tratto in inganno da trasposizioni di byte [HOL91].
CRC (Cyclic Redundancy Check)
Nel metodo CRC i dati che vengono aggiunti ad ogni unità corrispondono al resto ottenuto da una particolare divisione di un polinomio, detto generatrice, che dipende dalle dimensioni dell’unità. Per esempio, la generatrice di un’unità di 9 bit può essere “x8 + x4 + x3 + x2 +1” e corrisponde a “100011101”.
Questo algoritmo rappresenta il criterio più affidabile nella trasmissione dei dati ed è anche utilizzato nei sistemi di registrazione dei dati su hard disk [GIA].
Tutti i metodi riportati permettono il rilevamento di eventuali errori, ma purtroppo non permettono la correzione. In caso di errori si ha quindi la ritrasmissione totale o parziale dei dati, a seconda della complessità dell’algoritmo scelto e della gravità dell’errore.
La modulazione permette agli apparecchi RFID di trasmettere le informazioni di origine digitale (1 o 0) attraverso onde elettromagnetiche (analogiche). Negli ambienti in cui avvengono queste trasmissioni però spesso ci possono essere ostacoli ed elementi di disturbo che possono fare ridurre la probabilità di una corretta interpretazione del circuito di demodulazione. Inoltre i sistemi RFID passivi hanno l’obiettivo di trasferire la maggior quantità di energia possibile tra il reader e il transponder. Per questi motivi viene attuata la codifica dei dati [REN].
Tecniche di base: NRZ, RZ, Manchester e Miller
Esistono numerosi metodi per effettuare la codifica dei dati. Di seguito sono elencati i più semplici e i più utilizzati.
NRZ (No Return to Zero)
Lo stato digitale “1” è rappresentato con un segnale alto.
Lo stato digitale “0” è rappresentato con un segnale basso (fig. 3.5).
Questo metodo è facilmente ottenibile e non richiede circuiti complicati anche perché non si tratta di una vera e propria codifica, visto che i dati vengono passati direttamente come tali in uscita. Si ha inoltre una alta robustezza agli errori, anche se lunghe stringhe di “0” o di “1” potrebbero causare la perdita del sincronismo.
Codifica NRZ
RZ (Return to Zero)
Lo stato digitale “1” è rappresentato con un segnale alto.
Lo stato digitale “0” è rappresentato con un segnale basso.
Ad ogni semiperiodo il segnale torna sempre a zero (fig. 3.6).
Come nel metodo precedente, non si ha una vera e propria codifica dei dati. Il ricevitore deve però distinguere tra 3 livelli, anziché tra 2; quindi la probabilità di errore è più grande rispetto a quella che si ha nell’NRZ. Il vantaggio è che lunghe stringhe di “0” o di “1” non causano la perdita del sincronismo [SCH].
Codifica RZ
Manchester
Lo stato digitale “1” è rappresentato con una transizione al semiperiodo fra il segnale alto e il segnale basso.
Lo stato digitale “1” è rappresentato con una transizione al semiperiodo fra il segnale basso e il segnale alto (fig. 3.7).
Come nell’RZ, in questo metodo lunghe stringhe di “0” o “1” non causano la perdita del sincronismo. Inoltre, lavorando con solo due livelli, viene garantita un’alta robustezza agli errori. La codifica Manchester richiede un circuito più complicato rispetto a quelli per l’RZ e l’NRZ.
Codifica Manchester
Miller
Lo stato digitale “1” è rappresentato mantenendo all’inizio del periodo il livello dello stato precedente e attuando una transizione al semiperiodo.
Lo stato digitale “0” è rappresentato in uno di questi due modi:
Se lo stato precedente era un “1”, viene mantenuto il livello per tutto il periodo.
Se lo stato precedente era uno “0”, si ha una transizione all’inizio del periodo e poi si mantiene il livello costante per tutto il periodo (fig. 3.8). Questo metodo ha gli stessi vantaggi della codifica Manchester, ma richiede un circuito più complicato perché necessita di una memoria [SCH].
Il nostro sito utilizza i cookies per offrirti un servizio migliore.
Se vuoi saperne di più o avere istruzioni dettagliate su come disabilitare l'uso dei cookies puoi leggere l' informativa estesa.
Cliccando in un punto qualsiasi dello schermo, effettuando un’azione di scroll o cliccando su Accetto, presti il consenso all’uso di tutti i cookies.OkNoPrivacy policy