
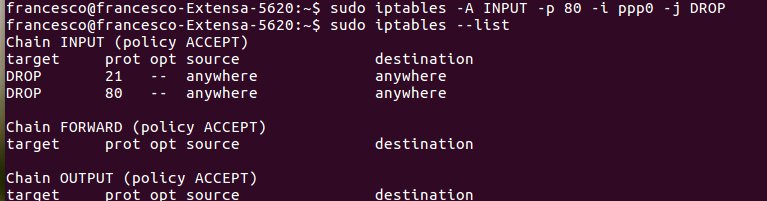
[:it]

Claude Monet
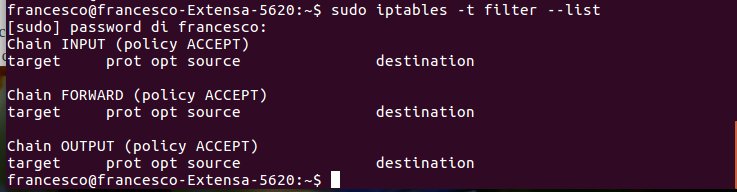
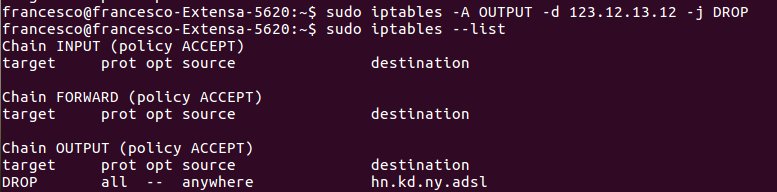
Nel post precedente avevo usato il comando
useradd -G nomegruppo nomeutente
tale comando se non abbinato all’opzione -m non crea la home directory.
Il comando per la creazione della home directory diventa pertanto:
useradd -G nomegruppo nomeutente -m
Esso pertanto è comodo se si è cancellato un utente e lo si vuole ricreare sapendo che la sua home directory esiste già.
Il comando nativo, se si vuole anche fornire ulteriori informazioni è:
adduser con le opzioni precedenti.
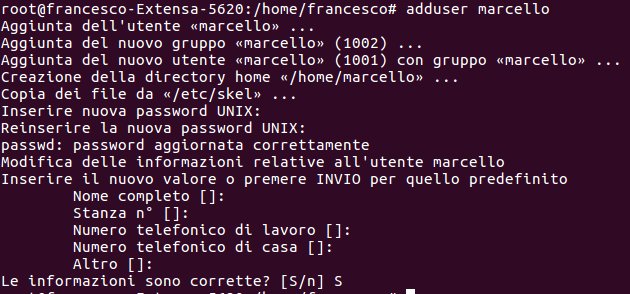
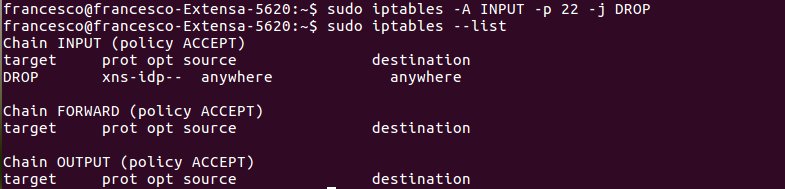
Per vedere adesso l’elenco degli utenti si deve usare il comando
cat /etc/passwd
in particolare se si vuole sapere quali sono gli utenti che hanno una home si usa il comando:
cat /etc/passwd | grep home/
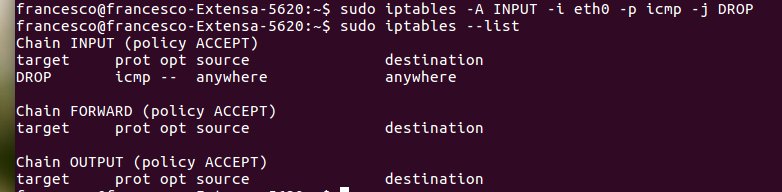
Verifica permessi sui file
Con il comando
ls -al
si vedono tutti i permessi di un file o directory

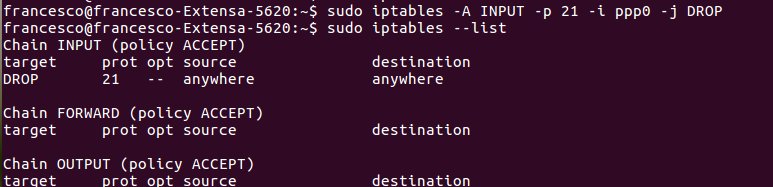
La colonna dei permessi contiene 10 lettere (o trattini):
- il primo spazio i ndica la tipologia dell’elemento e può avere i seguenti valori: d (directory), l(link simbolico), – (file);
- i seguenti nove spazi indicano i permessi; più precisamente si tratta di tre distinti gruppi di 3 permessi (r = lettura; w = scrittura; x = esecuzione). Il primo gruppo da tre riguarda il proprietario, il secondo riguarda il gruppo ed il terzo riguarda gli altri utenti.
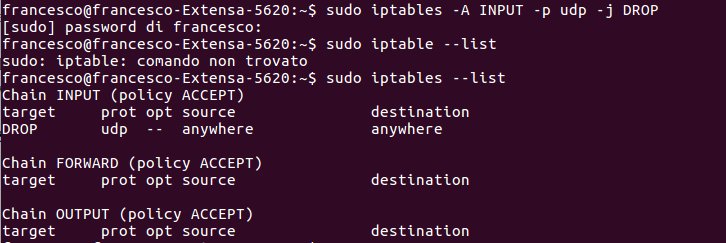
Comando che cambia i permessi chmod
Ad esempio il comando:
chmod a=rwx nomefile
si assegna a tutti la rwx
L’assegnatario viene identificato attraverso una lettera:
- a (tutti)
- u (utente proprietario)
- g (gruppo)
- o (altri utenti)
Si può usare anche la notazione ottale:
chmod 777 nomefile
Di seguito una tabella dei valori numerici e del loro significato:
- 7 corrisponde a rwx
- 6 corrisponde a rw
- 5 corrisponde a rx
- 4 corrisponde a r
- 3 corrisponde a wx
- 2 corrisponde a w
- 1 corrisponde a x
- 0 negato ogni accesso
Cambio nome proprietario e gruppo chown e chgrp
Il comando chown è utilizzato per cambiare l’utente proprietario e/o il gruppo assegnato ad un file o ad una directory. La sintassi di chown è molto semplice:
chown marcello:programmatori esercizio1
se voglio invece cambiare solo il gruppo
chgrp programmatori esercizio1

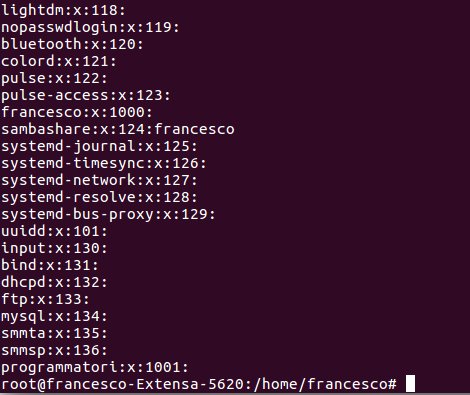
Adesso l’utente marcello che è all’interno del gruppo programmatori non può cambiare il file documento senza titolo1 ma può cambiare il documento esercizio1.
Cancellazione gruppo secondario
cancello il gruppo programmatori
delgroup programmatori
la lista dei file sarà:

Adesso appena aggiungo un nuovo gruppo esso prenderà il GID 1001.
Aggiunta utente in ambiente con samba attivo:
si usa il comando:
smbldap -useradd -a -m nomeutente
[:]


 [:]
[:]








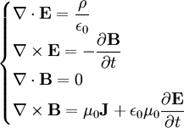 La teoria del campo elettromagnetico è sintetizzata in quattro leggi. Esse sono chiamate equazioni di Maxwell poiché fu Maxwell che, oltre a formulare la quarta legge, comprese che esse costituiscono il fondamento essenziale della teoria delle iterazioni elettromagnetiche.
La teoria del campo elettromagnetico è sintetizzata in quattro leggi. Esse sono chiamate equazioni di Maxwell poiché fu Maxwell che, oltre a formulare la quarta legge, comprese che esse costituiscono il fondamento essenziale della teoria delle iterazioni elettromagnetiche.
 .
.



 densità di carica volumetrica.
densità di carica volumetrica.


 superficie della base della lastra.
superficie della base della lastra.


 densità di carica superficiale.
densità di carica superficiale.
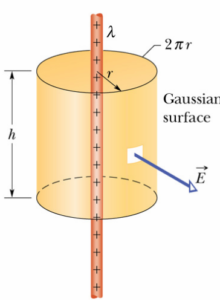 Campo elettrico di un filo carico infinitamente lungo
Campo elettrico di un filo carico infinitamente lungo
 base del cilindro (filo) e
base del cilindro (filo) e  lunghezza del filo.
lunghezza del filo.
 con
con densità lineare di carica.
densità lineare di carica. e si calcoli il flusso del campo elettrico
e si calcoli il flusso del campo elettrico  da essa prodotta attraverso una superficie sferica avente il centro coincidente con la carica.
da essa prodotta attraverso una superficie sferica avente il centro coincidente con la carica.
 ,
,  ,
,  ,…Su ciascuna di esse si può disegnare un vettore unitario
,…Su ciascuna di esse si può disegnare un vettore unitario  ,
,  ,
, ,…perpendicolare alla superficie in quel punto.
,…perpendicolare alla superficie in quel punto. ,
,  ,
,  ,… (theta) gli angoli tra i vettori normali
,… (theta) gli angoli tra i vettori normali  ,
,  ,
,  ,… in ogni punto della superficie.
,… in ogni punto della superficie. del campo vettoriale
del campo vettoriale  attraverso la superficie S è:
attraverso la superficie S è:




 lungo la direzione radiale .
lungo la direzione radiale .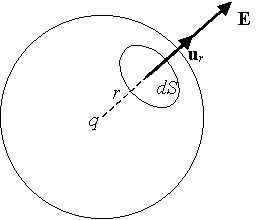
 fra il campo elettrico e il vettore unitario normale è nullo e
fra il campo elettrico e il vettore unitario normale è nullo e  .
. .
.